การทแยงมุมแบบควอนตัม Krylov
ในบทเรียนเรื่องการทแยงมุมแบบควอนตัม Krylov (KQD) เราจะตอบคำถามต่อไปนี้:
- วิธีการ Krylov คืออะไร โดยทั่วไปแล้ว?
- วิธีการ Krylov ทำงานอย่างไร และภายใต้เงื่อนไขใด?
- การคำนวณเชิงควอนตัมมีบทบาทอย่างไร?
ส่วนที่เกี่ยวกับการคำนวณเชิงควอนตัมอิงจากงานวิจัยใน Ref [1] เป็นหลัก
วิดีโอด้านล่างให้ภาพรวมของวิธีการ Krylov ในการคำนวณแบบคลาสสิก กระตุ้นให้เห็นประโยชน์ของวิธีการนี้ และอธิบายว่าการคำนวณเชิงควอนตัมสามารถเข้ามามีบทบาทได้อย่างไร ข้อความที่ตามมาให้รายละเอียดเพิ่มเติมและนำวิธีการ Krylov ไปใช้งานทั้งในเชิงคลาสสิกและบนคอมพิวเตอร์ควอนตัม
1. บทนำสู่วิธีการ Krylov
วิธีการ Krylov subspace อาจหมายถึงวิธีการหลายอย่างที่สร้างขึ้นรอบสิ่งที่เรียกว่า Krylov subspace การทบทวนอย่างครอบคลุมอยู่นอกขอบเขตของบทเรียนนี้ แต่ Ref [2-4] สามารถให้ข้อมูลพื้นฐานเพิ่มเติมได้มาก ที่นี่เราจะมุ่งเน้นว่า Krylov subspace คืออะไร ทำงานอย่างไรและทำไมจึงมีประโยชน์ในการแก้ปัญหาค่าเจาะจง และสุดท้ายสามารถนำไปใช้บนคอมพิวเตอร์ควอนตัมได้อย่างไร นิยาม: กำหนด matrix ขนาด ที่สมมาตรและกึ่งบวกแน่นอน Krylov space อันดับ คือ space ที่ขึงโดยเวกเตอร์ที่ได้จากการคูณกำลังสูงขึ้นของ matrix ถึง กับเวกเตอร์อ้างอิง
แม้เวกเตอร์ข้างต้นจะขึง Krylov subspace แต่ไม่มีเหตุผลที่คิดว่าจะตั้งฉากซึ่งกันและกัน มักใช้กระบวนการ orthonormalize แบบวนซ้ำที่คล้ายกับ Gram-Schmidt orthogonalization กระบวนการที่นี่แตกต่างเล็กน้อยตรงที่เวกเตอร์ใหม่แต่ละตัวจะถูกทำให้ตั้งฉากกับตัวอื่นในขณะที่สร้างขึ้น ในบริบทนี้เรียกว่า Arnoldi iteration เริ่มจากเวกเตอร์เริ่มต้น สร้างเวกเตอร์ถัดไป แล้วทำให้เวกเตอร์ที่สองตั้งฉากกับตัวแรกด้วยการลบการฉายบน ออก คือ
ตอนนี้เห็นได้ง่ายว่า เนื่องจาก
ทำแบบเดียวกันสำหรับเวกเตอร์ถัดไป ทำให้ตั้งฉากกับสองตัวก่อนหน้า:
ถ้าทำซ้ำกระบวนการนี้สำหรับเวกเตอร์ทั้ง ตัว จะได้ฐาน orthonormal ครบถ้วนสำหรับ Krylov space สังเกตว่ากระบวนการ orthogonalization จะให้ค่าศูนย์เมื่อ เนื่องจากเวกเตอร์ ตัวที่ตั้งฉากกันจำเป็นต้องขึง space เต็ม กระบวนการจะให้ค่าศูนย์ด้วยถ้าเวกเตอร์ใดเป็น eigenvector ของ เพราะเวกเตอร์ที่ตามมาทั้งหมดจะเป็นผลคูณสเกลาร์ของเวกเตอร์นั้น
1.1 ตัวอย่างง่ายๆ: Krylov ด้วยมือ
มาดูกระบวนการสร้าง Krylov subspace บน matrix ขนาดเล็กมาก เพื่อให้เห็นกระบวนการ เริ่มจาก matrix ที่เราสนใจ:
สำหรับตัวอย่างเล็กๆ นี้ เราสามารถหา eigenvector และ eigenvalue ได้ง่ายแม้แต่ด้วยมือ เราแสดงผลลัพธ์เชิงตัวเลขที่นี่
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit qiskit-ibm-runtime scipy sympy
# One might use linalg.eigh here, but later matrices may not be Hermitian. So we use
# linalg.eig in this lesson.
import numpy as np
A = np.array([[4, -1, 0], [-1, 4, -1], [0, -1, 4]])
eigenvalues, eigenvectors = np.linalg.eig(A)
print("The eigenvalues are ", eigenvalues)
print("The eigenvectors are ", eigenvectors)
The eigenvalues are [2.58578644 4. 5.41421356]
The eigenvectors are [[ 5.00000000e-01 -7.07106781e-01 5.00000000e-01]
[ 7.07106781e-01 1.37464400e-16 -7.07106781e-01]
[ 5.00000000e-01 7.07106781e-01 5.00000000e-01]]
บันทึกไว้ที่นี่เพื่อเปรียบเทียบภายหลัง:
เราต้องการศึกษาว่ากระบวนการนี้ทำงาน (หรือล้มเหลว) อย่างไรเมื่อเพิ่มมิติของ Krylov subspace เพื่อจุดประสงค์นี้จะใช้กระบวนการ:
- สร้าง subspace ของ vector space เต็มโดยเริ่มจากเวกเตอร์ที่เลือกแบบสุ่ม (เรียกว่า ถ้า normalize แล้วตามข้างต้น)
- ฉาย matrix เต็ม ลงใน subspace นั้น และหา eigenvalue ของ matrix ที่ฉายแล้ว
- เพิ่มขนาด subspace ด้วยการสร้างเวกเตอร์เพิ่มเติม ทำให้ orthonormal โดยใช้กระบวนการคล้าย Gram-Schmidt orthogonalization
- ฉาย ลงใน subspace ที่ใหญ่ขึ้นและหา eigenvalue ของ matrix ผลลัพธ์
- ทำซ้ำจนกว่า eigenvalue จะลู่เข้า (หรือในตัวอย่างนี้จนกว่าจะสร้างเวกเตอร์ที่ขึง vector space เต็มของ matrix ต้นฉบับ)
การ implement วิธีการ Krylov ปกติไม่จำเป็นต้องแก้ปัญหา eigenvalue สำหรับ matrix ที่ฉายบน Krylov subspace ทุกขนาด สามารถสร้าง subspace ของมิติที่ต้องการ ฉาย matrix ลงใน subspace นั้น แล้วทแยงมุม matrix ที่ฉายแล้ว การฉายและทแยงมุมในแต่ละมิติของ subspace ทำเพื่อตรวจสอบการลู่เข้าเท่านั้น
มิติ :
เลือกเวกเตอร์สุ่ม เช่น
ถ้ายัง normalize ไม่ได้ ให้ normalize
ตอนนี้ฉาย matrix ลงใน subspace ของเวกเตอร์เดียวนี้:
นี่คือการฉาย matrix ลงใน Krylov subspace เมื่อมีเวกเตอร์เพียงตัวเดียว eigenvalue ของ matrix นี้คือ 4 อย่างชัดเจน ถือเป็นการประมาณ eigenvalue ลำดับศูนย์ (ในกรณีนี้มีแค่ตัวเดียว) ของ แม้จะเป็นการประมาณที่ไม่ดี แต่ก็อยู่ในลำดับความใหญ่ที่ถูกต้อง
มิติ :
ตอนนี้สร้างเวกเตอร์ถัดไปใน subspace โดยดำเนินการ บนเวกเตอร์ก่อนหน้า:
ตอนนี้ลบการฉายของเวกเตอร์นี้บนเวกเตอร์ก่อนหน้าออกเพื่อให้ตั้งฉาก
ถ้ายัง normalize ไม่ได้ ให้ normalize ในกรณีนี้เวกเตอร์ normalize แล้ว ดังนั้น
ตอนนี้ฉาย matrix A ลงใน subspace ของสองเวกเตอร์นี้:
ยังคงเหลือปัญหาการหา eigenvalue ของ matrix นี้ แต่ matrix นี้เล็กกว่า matrix เต็มเล็กน้อย ในปัญหาที่เกี่ยวข้อง matrix ขนาดใหญ่มาก การทำงานกับ subspace ที่เล็กกว่านี้อาจมีประโยชน์มาก
แม้ยังไม่ใช่การประมาณที่ดี แต่ดีกว่าการประมาณลำดับศูนย์ จะทำซ้ำอีกหนึ่งรอบเพื่อให้กระบวนการชัดเจน อย่างไรก็ตาม สิ่งนี้บั่นทอนจุดประสงค์ของวิธีการ เพราะในรอบถัดไปจะต้องทแยงมุม matrix ขนาด 3x3 ซึ่งหมายความว่าไม่ได้ประหยัดเวลาหรือพลังการคำนวณ
มิติ :
ตอนนี้สร้างเวกเตอร์ถัดไปใน subspace โดยดำเนินการ A บนเวกเตอร์ก่อนหน้า:
ตอนนี้ลบการฉายของเวกเตอร์นี้บนเวกเตอร์ก่อนหน้าทั้งสองออกเพื่อให้ตั้งฉาก
ถ้ายัง normalize ไม่ได้ ให้ normalize ในกรณีนี้เวกเตอร์ normalize แล้ว ดังนั้น
ตอนนี้ฉาย matrix ลงใน subspace ของเวกเตอร์เหล่านี้:
ตอนนี้หา eigenvalue:
eigenvalue เหล่านี้คือ eigenvalue ที่แน่นอนของ matrix ต้นฉบับ สิ่งนี้ต้องเกิดขึ้น เพราะเราขยาย Krylov subspace ให้ขึง vector space เต็มของ matrix ต้นฉบับ
ในตัวอย่างนี้ วิธีการ Krylov อาจไม่ดูง่ายกว่าการทแยงมุมโดยตรง จริงๆ แล้วอย่างที่เราจะเห็นในส่วนถัดไป วิธีการ Krylov ได้เปรียบก็ต่อเมื่อมิติของ matrix สูงกว่าค่าหนึ่ง ตัวอย่างนี้มีไว้เพื่อช่วยแก้ปัญหา eigenvalue/eigenvector ของ matrix ขนาดใหญ่มาก
นี่เป็นตัวอย่างเดียวที่แสดงการคำนวณ "ด้วยมือ" แต่ส่วนที่ 2 ด้านล่างแสดงตัวอย่างเชิงคำนวณ
คำอธิบายศัพท์
ความเข้าใจผิดที่พบบ่อยคือคิดว่ามี Krylov subspace เดียวสำหรับปัญหาที่กำหนด แต่แน่นอนว่าเนื่องจากมีเวกเตอร์เริ่มต้นหลายตัวที่ matrix สามารถดำเนินการได้ จึงมี Krylov subspace ที่เป็นไปได้หลายอย่าง เราจะใช้วลี "the Krylov subspace" เพื่อหมายถึง Krylov subspace เฉพาะที่กำหนดไว้แล้วสำหรับตัวอย่างเฉพาะ สำหรับแนวทางการแก้ปัญหาทั่วไปจะอ้างถึง "a Krylov subspace" คำอธิบายสุดท้ายคือถูกต้องที่จะอ้างถึง "Krylov space" บ่อยครั้งเรียกว่า "Krylov subspace" เนื่องจากใช้ในบริบทของการฉาย matrix จาก space เริ่มต้นลงใน subspace เพื่อให้สอดคล้องกับบริบทนั้น เราจะอ้างถึงเป็น subspace เป็นหลักที่นี่
ทดสอบความเข้าใจ
อ่านคำถามด้านล่าง คิดคำตอบ แล้วคลิกสามเหลี่ยมเพื่อดูแต่ละคำตอบ
อธิบายว่าทำไมจึงไม่ (a) มีประโยชน์ และ (b) เป็นไปได้ที่จะขยายมิติของ Krylov subspace เกินมิติ ของ matrix ที่สนใจ
คำตอบ:
(a) เนื่องจากเรา orthonormalize เวกเตอร์ในขณะที่สร้าง เวกเตอร์ ตัวดังกล่าวจะประกอบเป็นฐานครบถ้วน ซึ่งหมายความว่า combination เชิงเส้นของมันสามารถสร้างเวกเตอร์ใดๆ ใน space ได้ (b) กระบวนการ orthogonalization ประกอบด้วยการลบการฉายของเวกเตอร์ใหม่บนเวกเตอร์ก่อนหน้าทั้งหมด ถ้าเวกเตอร์ก่อนหน้าทั้งหมดขึง vector space เต็ม การลบการฉายบน subspace เต็มจะให้เวกเตอร์ศูนย์เสมอ
สมมติว่านักวิจัยเพื่อนร่วมงานกำลังสาธิตวิธีการ Krylov ที่ใช้กับ matrix ตัวอย่างเล็กๆ ให้เพื่อนร่วมงาน นักวิจัยคนนี้วางแผนใช้ matrix และเวกเตอร์เริ่มต้น:
และ
มีอะไรผิดพลาดหรือไม่? จะแนะนำเพื่อนร่วมงานอย่างไร?
คำตอบ:
เพื่อนร่วมงานของคุณเผลอเลือก eigenvector เป็นเวกเตอร์เริ่มต้น การดำเนินการ matrix บนเวกเตอร์เริ่มต้นจะให้เวกเตอร์เดิมคืน ปรับสเกลด้วย eigenvalue ซึ่งจะไม่สร้าง subspace ที่มีมิติเพิ่มขึ้น แนะนำเพื่อนร่วมงานให้เลือกเวกเตอร์เริ่มต้นอื่น ตรวจสอบให้แน่ใจว่าไม่ใช่ eigenvector
ใช้วิธีการ Krylov กับ matrix ด้านล่าง โดยเลือกเวกเตอร์เริ่มต้นที่เหมาะสมใหม่ เขียนการประมาณค่า eigenvalue ต่ำสุดที่ลำดับที่ 0 และที่ 1 ของ Krylov subspace ของคุณ
คำตอบ:
มีคำตอบที่เป็นไปได้หลายอย่างขึ้นอยู่กับการเลือกเวกเตอร์เริ่มต้น เราจะเลือก:
เพื่อให้ได้ ใช้ กับ หนึ่งครั้ง แล้วทำให้ ตั้งฉากกับ
ที่ลำดับที่ 0 การฉายลงใน Krylov subspace ของเราคือ
ที่ลำดับที่ 1 การฉายลงใน Krylov subspace นี้คือ
สามารถทำด้วยมือได้ แต่ง่ายที่สุดโดยใช้ numpy:
import numpy as np
vstar = np.array([[1/np.sqrt(3),1/np.sqrt(3),1/np.sqrt(3)],[-1/np.sqrt(6),np.sqrt(2/3),-1/np.sqrt(6)]]
)
A = np.array([[1, 1, 0],
[1, 1, 1],
[0, 1, 1]])
v = np.array([[1/np.sqrt(3),-1/np.sqrt(6)],[1/np.sqrt(3),np.sqrt(2/3)],[1/np.sqrt(3),-1/np.sqrt(6)]])
proj = vstar@A@v
print(proj)
eigenvalues, eigenvectors = np.linalg.eig(proj)
print("The eigenvalues are ", eigenvalues)
print("The eigenvectors are ", eigenvectors)
outputs:
[[ 2.33333333 0.47140452]
[ 0.47140452 -0.33333333]]
The eigenvalues are [ 2.41421356 -0.41421356]
The eigenvectors are [[ 0.98559856 -0.16910198]
[ 0.16910198 0.98559856]]
การประมาณ eigenvalue ต่ำสุดคือ -0.414
1.2 ประเภทของวิธีการ Krylov
"วิธีการ Krylov subspace" อาจหมายถึงเทคนิคแบบวนซ้ำหลายอย่างที่ใช้แก้ระบบสมการเชิงเส้นขนาดใหญ่และปัญหา eigenvalue สิ่งที่ทุกวิธีมีเหมือนกันคือสร้างคำตอบประมาณจาก Krylov subspace
โดยที่ คือการเดาเริ่มต้น (ดู Ref [5]) วิธีการเหล่านั้นแตกต่างกันในวิธีเลือกการประมาณที่ดีที่สุดจาก subspace นี้ โดยสมดุลปัจจัยต่างๆ เช่น อัตราการลู่เข้า การใช้หน่วยความจำ และค่าใช้จ่ายการคำนวณโดยรวม เป้าหมายของบทเรียนนี้คือใช้ประโยชน์จากการคำนวณเชิงควอนตัมในบริบทของวิธีการ Krylov subspace การอภิปรายอย่างละเอียดถี่ถ้วนอยู่นอกขอบเขต นิยามสั้นๆ ด้านล่างมีไว้เพื่อบริบทเท่านั้นและรวมถึงข้อมูลอ้างอิงสำหรับศึกษาวิธีการเหล่านี้เพิ่มเติม
วิธี conjugate gradient (CG): วิธีการนี้ใช้แก้ระบบสมการเชิงเส้นที่สมมาตรและบวกแน่นอน[6] ลดค่า A-norm ของ error ในแต่ละรอบวนซ้ำ ทำให้มีประสิทธิภาพเป็นพิเศษสำหรับระบบที่เกิดจาก PDE เชิง elliptic แบบแยกส่วน[7] เราจะใช้วิธีนี้ในส่วนถัดไปเพื่อกระตุ้นให้เห็นว่าทำไม Krylov subspace จึงเป็น subspace ที่มีประสิทธิภาพในการหาคำตอบที่ดีขึ้นสำหรับระบบสมการเชิงเส้น
วิธี generalized minimal residual (GMRES): ออกแบบมาสำหรับการแก้ระบบสมการเชิงเส้นทั่วไปที่ไม่สมมาตร ลด residual norm บน Krylov space ในแต่ละรอบวนซ้ำ ทำให้แข็งแกร่งแต่อาจใช้หน่วยความจำมากสำหรับระบบขนาดใหญ่[7]
วิธี minimal residual (MINRES): วิธีการนี้ใช้แก้ระบบสมการเชิงเส้นที่สมมาตรแบบไม่แน่นอน คล้ายกับ GMRES แต่ใช้ประโยชน์จากความสมมาตรของ matrix เพื่อลดค่าใช้จ่ายการคำนวณ[8]
แนวทางอื่นที่น่าสนใจ ได้แก่ full orthogonalization method (FOM) ซึ่งเกี่ยวข้องกับวิธีของ Arnoldi สำหรับปัญหา eigenvalue, bi-conjugate gradient (BiCG) method, และ induced dimension reduction (IDR) method
1.3 ทำไมวิธีการ Krylov subspace จึงได้ผล
ที่นี่เราจะแสดงเหตุผลว่าวิธีการ Krylov subspace ควรเป็นวิธีที่มีประสิทธิภาพในการประมาณ eigenvalue ของ matrix ผ่านการปรับปรุง eigenvector แบบวนซ้ำ โดยมองผ่านเลนส์ของ steepest descent เราจะโต้แย้งว่าเมื่อกำหนดการเดาเริ่มต้นของ ground state space ของการแก้ไขที่ต่อเนื่องกันที่ให้การลู่เข้าเร็วที่สุดคือ Krylov subspace เราหยุดก่อนถึงการพิสูจน์อย่างเข้มงวดของพฤติกรรมการลู่เข้า
สมมติว่า matrix ที่เราสนใจสมมาตรและบวกแน่นอน สิ่งนี้ทำให้ข้อโต้แย้งของเราเกี่ยวข้องกับวิธี CG ข้างต้นมากที่สุด เราไม่ตั้งสมมติฐานเกี่ยวกับความเบาบางที่นี่ และเราไม่ได้อ้างว่า ต้องเป็น Hermitian (ซึ่งจำเป็นถ้าเป็น Hamiltonian)
เราต้องการแก้ปัญหาในรูปแบบ
อาจจินตนาการว่า โดยที่ คือค่าคงที่ เช่นในปัญหา eigenvalue แต่คำกล่าวปัญหาของเรายังคงทั่วไปกว่าตอนนี้
เริ่มจากเวกเตอร์ ที่เป็นคำตอบประมาณ แม้มีความคล้ายกันระหว่างการเดา นี้และ ในส่วน 1.1 เราไม่ได้ใช้ประโยชน์จากสิ่งเหล่านี้ที่นี่ การเดา มี error ซึ่งเรียกว่า
นิยาม residual
ที่นี่ใช้ตัวพิมพ์ใหญ่ เพื่อแยกความแตกต่างจาก residual กับมิติของ Krylov subspace

ตอนนี้ต้องการทำขั้นตอนการแก้ไขในรูปแบบ
ซึ่งหวังว่าจะปรับปรุงการประมาณ ที่นี่ คือเวกเตอร์ที่ยังต้องกำหนด ให้ คือ error หลังการแก้ไข แล้ว

เราสนใจพฤติกรรมของ error เมื่อแปลงโดย matrix จึงคำนวณ -norm ของ error คือ
โดยใช้ความสมมาตรของ และที่ ที่นี่ คือค่าคงที่ที่ไม่ขึ้นกับ ดังที่กล่าวในส่วน 1.2 -norm ของ error ไม่ใช่ปริมาณเดียวที่เราอาจเลือกลดค่า แต่เป็นปริมาณที่ดี เราต้องการดูว่าปริมาณนี้เปลี่ยนแปลงอย่างไรตามการเลือก correction vector จึงนิยามฟังก์ชัน โดย
คือ error เป็นฟังก์ชันของการแก้ไข วัดใน -norm ดังนั้นต้องการเลือก ให้ เล็กที่สุด เพื่อจุดประสงค์นี้คำนวณ gradient ของ โดยใช้ความสมมาตรของ จะได้
gradient ชี้ไปในทิศทางของ steepest ascent ซึ่งหมายความว่าทิศทางตรงข้ามให้ทิศทางที่ฟังก์ชันลดลงมากที่สุด: ทิศทางของ steepest descent ที่การเดาเริ่มต้น โดยที่ จะได้ ดังนั้นฟังก์ชัน ลดลงมากที่สุดในทิศทางของ residual การเลือกเริ่มต้นของเราจะได้ประโยชน์มากที่สุดจากการเพิ่ม สำหรับสเกลาร์ บางค่า
ในขั้นตอนถัดไป เราเลือกเวกเตอร์ อีกครั้งและเพิ่มค่าของมันเข้ากับการประมาณปัจจุบัน โดยใช้ข้อโต้แย้งเดียวกับก่อนหน้า เราเลือก สำหรับสเกลาร์ บางค่า ดำเนินการต่อในลักษณะนี้ โดยที่การวนซ้ำที่ ของเวกเตอร์คือ
หรือกล่าวอีกนัยหนึ่ง ต้องการสร้าง space ที่เลือกการประมาณที่ดีขึ้นโดยการเพิ่ม , และต่อๆ ไปตามลำดับ เวกเตอร์ที่ประมาณที่ อยู่ใน
ตอนนี้โดยใช้ความสัมพันธ์ว่า
เราเห็นว่า
นั่นคือ space ที่สร้างขึ้นซึ่งประมาณคำตอบที่ถูกต้อง ได้มีประสิทธิภาพที่สุดคือ space ที่สร้างขึ้นโดยการดำเนินการ matrix บน อย่างต่อเนื่อง Krylov subspace คือ space ที่ขึงโดยเวกเตอร์ของทิศทาง steepest descent ที่ต่อเนื่องกัน
สุดท้ายเน้นย้ำว่าเราไม่ได้ตั้งข้อกล่าวอ้างเชิงตัวเลขเกี่ยวกับการปรับขนาดของวิธีนี้ และไม่ได้อภิปรายถึงประโยชน์ที่เปรียบเทียบได้สำหรับ matrix แบบเบาบาง นี่เป็นเพียงการกระตุ้นให้เห็นการใช้งานวิธีการ Krylov subspace และเพิ่มความเข้าใจใน intuition สำหรับมัน ตอนนี้จะสำรวจพฤติกรรมของวิธีการเหล่านี้ทางตัวเลข
ทดสอบความเข้าใจ
อ่านคำถามด้านล่าง คิดคำตอบ แล้วคลิกสามเหลี่ยมเพื่อดูคำตอบ
ในขั้นตอนการทำงานข้างต้น เราเสนอการลด -norm ของ error ปริมาณอื่นๆ อะไรที่อาจพิจารณาในการหา ground state และ eigenvalue ของมัน?
คำตอบ:
อาจใช้เวกเตอร์ residual แทน -norm ของ error อาจมีกรณีที่การพิจารณาเวกเตอร์ error เองมีประโยชน์
2. วิธีการ Krylov ในการคำนวณแบบคลาสสิก
ในส่วนนี้เราจะ implement Arnoldi iterations เชิงคำนวณเพื่อใช้ประโยชน์จาก Krylov subspace ในการแก้ปัญหา eigenvalue เราจะใช้กับตัวอย่างขนาดเล็กก่อน จากนั้นตรวจสอบว่าเวลาการคำนวณปรับขนาดอย่างไรเมื่อขนาดของ matrix ที่สนใจเพิ่มขึ้น แนวคิดสำคัญที่นี่คือการสร้างเวกเตอร์ที่ขึง Krylov space จะเป็นตัวสร้างเวลาการคำนวณหลัก ความต้องการหน่วยความจำจะแตกต่างกันระหว่างวิธีการ Krylov เฉพาะ แต่ข้อจำกัดด้านหน่วยความจำสามารถจำกัดการใช้วิธีการ Krylov แบบดั้งเดิม
2.1 ตัวอย่างขนาดเล็กอย่างง่าย
ในกระบวนการสร้าง Krylov subspace เราจะต้อง orthonormalize เวกเตอร์ใน subspace นิยามฟังก์ชันที่รับเวกเตอร์ที่กำหนดแล้วจาก subspace vknown (ไม่จำเป็นต้อง normalize) และเวกเตอร์ที่เป็นตัวเลือกเพื่อเพิ่มลงใน subspace vnext แล้วทำให้ vnext ตั้งฉากกับ vknown และ normalize นอกจากนี้นิยามฟังก์ชันที่ผ่านกระบวนการนี้สำหรับเวกเตอร์ที่กำหนดทั้งหมดใน Krylov subspace เพื่อให้ได้ชุดที่ orthonormal ครบถ้วน
# vknown is some established vector in our subspace. vnext is one we wish to add,
# which must be orthogonal to vknown.
def orthog_pair(vknown, vnext):
vknown = vknown / np.sqrt(vknown.T @ vknown)
diffvec = vknown.T @ vnext * vknown
vnext = vnext - diffvec
return vnext
# v is the candidate vector to be added to our subspace. s is the existing subspace.
def orthoset(v, s):
v = v / np.sqrt(v.T @ v)
temp = v
for i in range(len(s)):
temp = orthog_pair(s[i], temp)
v = temp / np.sqrt(temp.T @ temp)
return v
ตอนนี้นิยามฟังก์ชันที่สร้าง Krylov subspace ที่ใหญ่ขึ้นเรื่อยๆ จนกว่า space ของ Krylov vector จะขึง space เต็มของ matrix ต้นฉบับ สิ่งนี้จะช่วยให้เราดูว่า eigenvalue ที่ได้จากวิธีการ Krylov subspace ตรงกับค่าที่แน่นอนดีแค่ไหน เป็นฟังก์ชันของมิติของ Krylov subspace อย่างสำคัญ ฟังก์ชัน krylov_full_build คืน Krylov vector, Hamiltonian ที่ฉาย, eigenvalue และเวลาที่ใช้
# Necessary imports and definitions to track time in microseconds
import time
def time_mus():
return int(time.time() * 1000000)
# This function constructs a Krylov subspace that spans the whole space of the original matrix.
# Input:
# v0 : initial vector
# matrix : original matrix to be diagonalized
# Output:
# ks : Krylov vectors
# Hs : projected Hamiltonians
# eigs : eigenvalues
# k_tot_times : time required for the operation
def krylov_full_build(v0, matrix):
t0 = time_mus()
b = v0 / np.sqrt(v0 @ v0.T)
A = matrix
ks = []
ks.append(b)
Hs = []
eigs = []
Hs.append(b.T @ A @ b)
eigs.append(np.array([b.T @ A @ b]))
k_tot_times = []
for j in range(len(A) - 1):
vec = A @ ks[j].T
ortho = orthoset(vec, ks)
ks.append(ortho)
ksarray = np.array(ks)
Hs.append(ksarray @ A @ ksarray.T)
eigs.append(np.linalg.eig(Hs[j + 1]).eigenvalues)
k_tot_times.append(time_mus() - t0)
# Return the Krylov vectors, the projected Hamiltonians, the eigenvalues,
# and the total time required.
return (ks, Hs, eigs, k_tot_times)
เราจะทดสอบกับ matrix ที่ยังค่อนข้างเล็ก แต่ใหญ่กว่าที่ต้องการทำด้วยมือ
# Define our small test matrix
test_matrix = np.array(
[
[4, -1, 0, 1, 0],
[-1, 4, -1, 2, 1],
[0, -1, 4, 3, 3],
[1, 2, 3, 4, 0],
[0, 1, 3, 0, 4],
]
)
# Give the test matrix and an initial guess as arguments in the function defined above.
# Calculate outputs.
test_ks, test_Hs, test_eigs, text_k_tot_times = krylov_full_build(
np.array([0.5, 0.5, 0, 0.5, 0.5]), test_matrix
)
เราสามารถตรวจสอบฟังก์ชันได้โดยให้แน่ใจว่าในขั้นตอนสุดท้าย (เมื่อ Krylov space คือ vector space เต็มของ matrix ต้นฉบับ) eigenvalue จากวิธีการ Krylov ตรงกับของการทแยงมุมเชิงตัวเลขที่แน่นอนพอดี:
print(np.linalg.eig(test_matrix).eigenvalues)
print(test_eigs[len(test_matrix) - 1])
[-1.36956923 8.43756009 2.9040308 5.34436028 4.68361806]
[-1.36956923 8.43756009 2.9040308 4.68361806 5.34436028]
สำเร็จแล้ว แน่นอนว่าสิ่งที่สำคัญจริงๆ คือการประมาณดีแค่ไหนเป็นฟังก์ชันของมิติของ Krylov subspace เนื่องจากมักสนใจหา ground state และ eigenvalue ต่ำสุดอื่นๆ (และด้วยเหตุผลเชิงพีชคณิตที่อธิบายด้านล่าง) มาดูการประมาณ eigenvalue ต่ำสุดเป็นฟังก์ชันของมิติของ Krylov subspace คือ
def errors(matrix, krylov_eigs):
targ_min = min(np.linalg.eig(matrix).eigenvalues)
err = []
for i in range(len(matrix)):
err.append(min(krylov_eigs[i]) - targ_min)
return err
import matplotlib.pyplot as plt
krylov_error = errors(test_matrix, test_eigs)
plt.plot(krylov_error)
plt.axhline(y=0, color="red", linestyle="--") # Add dashed red line at y=0
plt.xlabel("Order of Krylov subspace") # Add x-axis label
plt.ylabel("Error in minimum eigenvalue") # Add y-axis label
plt.show()
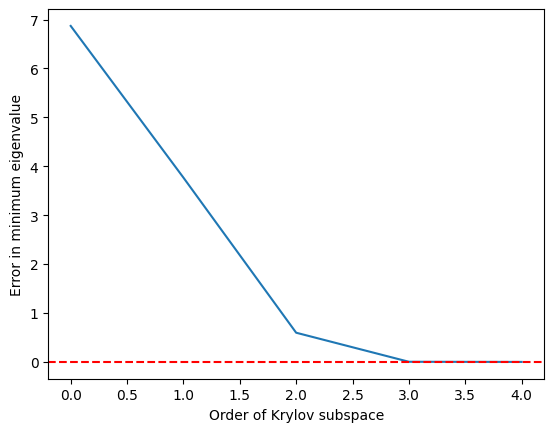
เห็นว่า eigenvalue ต่ำสุดถูกประมาณค่อนข้างแม่นยำเมื่อ Krylov subspace เติบโตถึง และสมบูรณ์แบบเมื่อถึง
2.2 การปรับขนาดเวลาตามมิติของ matrix
มาโน้มน้าวใจตัวเองว่าวิธีการ Krylov สามารถได้เปรียบเหนือ eigensolver เชิงตัวเลขโดยตรงในลักษณะต่อไปนี้:
- สร้าง matrix สุ่ม (ไม่เบาบาง ไม่ใช่แอปพลิเคชันในอุดมคติของ KQD)
- หา eigenvalue โดยใช้สองวิธี: โดยตรงโดยใช้ NumPy และใช้ Krylov subspace
- เลือก cutoff สำหรับความแม่นยำที่ eigenvalue ต้องมี ก่อนที่เราจะยอมรับการประมาณของ Krylov
- เปรียบเทียบ wall time ที่ใช้ในการแก้สองวิธี
ข้อควรระวัง: ดังที่จะอภิปรายอย่างละเอียดด้านล่าง การทแยงมุมแบบควอนตัม Krylov เหมาะสมที่สุดสำหรับตัวดำเนินการที่มีการแสดง matrix แบบเบาบาง และ/หรือสามารถเขียนโดยใช้กลุ่ม Pauli operators ที่สับเปลี่ยนได้จำนวนน้อย matrix สุ่มที่เราใช้ที่นี่ไม่ตรงกับคำอธิบายนั้น สิ่งเหล่านี้มีประโยชน์ในการทดสอบขนาดที่วิธีการ Krylov แบบคลาสสิกอาจมีประโยชน์ ประการที่สอง ในการใช้วิธีการ Krylov เราจะคำนวณ eigenvalue โดยใช้ Krylov subspace หลายขนาดที่แตกต่างกัน เราจะรายงานเวลาที่ใช้สำหรับ Krylov subspace มิติต่ำสุดที่ให้ความแม่นยำที่ต้องการสำหรับ eigenvalue ของ ground state อีกครั้ง สิ่งนี้แตกต่างเล็กน้อยจากการแก้ปัญหาที่ไม่สามารถจัดการได้สำหรับ eigensolver แบบแน่นอน เนื่องจากเราใช้คำตอบแน่นอนเพื่อประเมินมิติที่ต้องการ
เริ่มจากการสร้างชุด matrix สุ่ม
import numpy as np
# Set the random seed
np.random.seed(42)
# how many random matrices will we make
num_matrix = 200
matrices = []
for m in range(1, num_matrix):
matrices.append(np.random.rand(m, m))
ตอนนี้ทแยงมุม matrix แต่ละตัวโดยตรงโดยใช้ numpy คำนวณเวลาที่ใช้เพื่อเปรียบเทียบในภายหลัง
matrix_numpy_times = []
matrix_numpy_eigs = []
for mm in range(num_matrix - 1):
t0 = time_mus()
matrix_numpy_eigs.append(min(np.linalg.eig(matrices[mm]).eigenvalues))
matrix_numpy_times.append(time_mus() - t0)
plt.plot(matrix_numpy_times)
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (microsec)") # Add y-axis label
plt.show()
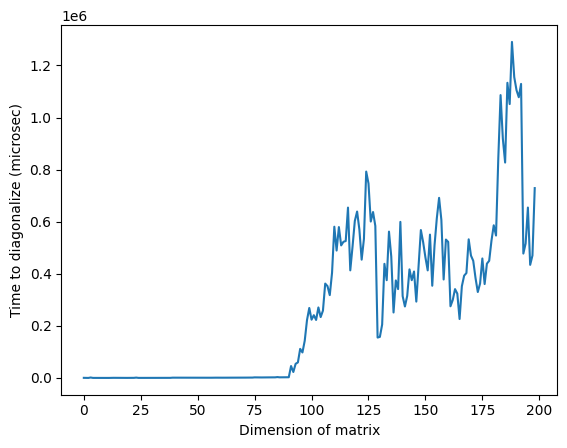
สังเกตว่าในภาพข้างต้น เวลาที่สูงผิดปกติรอบมิติ 125 อาจเกิดจากลักษณะสุ่มของ matrix หรือจากการ implement บน processor แบบคลาสสิกที่ใช้ แต่ไม่สามารถทำซ้ำได้ การรันโค้ดซ้ำจะให้ profile ที่แตกต่างกันพร้อม peak ผิดปกติที่แตกต่างกัน
ตอนนี้สำหรับแต่ละ matrix เราจะสร้าง Krylov subspace ทีละขั้นตอนและคำนวณ eigenvalue ในแต่ละขั้นตอน เราจะตรวจสอบว่า eigenvalue ต่ำสุดได้รับภายใน absolute error ที่ระบุหรือยัง subspace แรกที่ให้ eigenvalue ภายใน error ที่ระบุคือ subspace ที่เราจะบันทึกเวลาการคำนวณ การ execute cell นี้อาจใช้เวลาหลายนาทีขึ้นอยู่กับความเร็ว processor ข้ามการ evaluate หรือลดมิติสูงสุดของ matrix ที่ทแยงมุมได้ การดูผลลัพธ์ที่คำนวณล่วงหน้าก็เพียงพอ
# Choose the absolute error you can tolerate, and make a list for tracking the Krylov subspace size
# at which that error is achieved.
abserr = 0.05
accept_subspace_size = []
# Lists to store total time spent on the Krylov method, and the subset of that time spent on
# diagonalizing the projected matrix.
matrix_krylov_tot_times = []
matrix_krylov_dim = []
# Step through all our random matrices
for mm in range(0, num_matrix - 1):
test_ks, test_Hs, test_eigs, test_k_tot_times = krylov_full_build(
np.ones(len(matrices[mm])), matrices[mm]
)
# We have not yet found a Krylov subspace that produces our minimum eigenvalue to
# within the required error.
found = 0
for j in range(0, len(matrices[mm]) - 1):
# If we still haven't found the desired subspace...
if found == 0:
# ...but if this one satisfies the requirement, then record everything
if (
abs((min(test_eigs[j]) - matrix_numpy_eigs[mm]) / matrix_numpy_eigs[mm])
< abserr
):
accept_subspace_size.append(j)
matrix_krylov_tot_times.append(test_k_tot_times[j])
matrix_krylov_dim.append(mm)
found = 1
มาพล็อตเวลาที่ได้สำหรับสองวิธีนี้เพื่อเปรียบเทียบ:
plt.plot(matrix_numpy_times, color="blue")
plt.plot(matrix_krylov_dim, matrix_krylov_tot_times, color="green")
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (microsec)") # Add y-axis label
plt.show()

นี่คือเวลาจริงที่ใช้ แต่เพื่อจุดประสงค์ในการอภิปราย มา smooth เส้นโค้งเหล่านี้โดยเฉลี่ยจุดที่อยู่ติดกัน / มิติของ matrix ทำด้านล่าง:
smooth_numpy_times = []
smooth_krylov_times = []
# Choose the number of adjacent points over which to average forward;
# the same will be used backward.
smooth_steps = 10
# We will do this smoothing for all points/matrix dimensions
for i in range(len(matrix_krylov_tot_times)):
# Ensure we don't exceed the boundaries of our lists
start = max(0, i - smooth_steps)
end = min(len(matrix_krylov_tot_times) - 1, i + smooth_steps)
# Dummy variables for accumulating an average over adjacent points. This is done for both Krylov
# and the NumPy calculations.
smooth_count = 0
smooth_numpy_sum = 0
smooth_krylov_sum = 0
for j in range(start, end):
smooth_numpy_sum = smooth_numpy_sum + matrix_numpy_times[j]
smooth_krylov_sum = smooth_krylov_sum + matrix_krylov_tot_times[j]
smooth_count = smooth_count + 1
# Appending the averaged adjacent values to our new smooth lists
smooth_numpy_times.append(smooth_numpy_sum / smooth_count)
smooth_krylov_times.append(smooth_krylov_sum / smooth_count)
plt.plot(smooth_numpy_times, color="blue")
plt.plot(smooth_krylov_times, color="green")
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (smoothed, microsec)") # Add y-axis label
plt.show()

สังเกตว่าเวลาที่ใช้ในการสร้าง Krylov subspace ในตอนแรกเกินเวลาที่ numpy ใช้ทแยงมุมเต็ม แต่เมื่อขนาดของ matrix เติบโตขึ้น วิธีการ Krylov ได้เปรียบ สิ่งนี้เป็นจริงแม้จะลด error ที่ยอมรับได้ แต่ข้อได้เปรียบเกิดขึ้นที่ขนาด matrix ที่ใหญ่กว่า ควรวิเคราะห์สิ่งนี้
ความซับซ้อนของเวลาในการทแยงมุมเชิงตัวเลขคือ (มีความแตกต่างบ้างในแต่ละ algorithm) ความซับซ้อนของเวลาในการสร้างฐาน orthonormal ของ เวกเตอร์ก็คือ ดังนั้นข้อได้เปรียบของวิธีการ Krylov ไม่ เกี่ยวข้องกับการใช้ฐาน orthonormal บาง ตัว แต่เกี่ยวกับการใช้ฐาน orthonormal เฉพาะที่ค้นหา eigenvalue ที่สนใจได้อย่างมีประสิทธิภาพ เราได้เห็นสิ่งนี้จากการร่างหลักฐานในส่วนแรกของบทเรียนนี้ และนี่เป็นสิ่งสำคัญสำหรับการรับประกันการลู่เข้าในวิธีการ Krylov มาทบทวนความก้าวหน้าจนถึงตอนนี้:
- สำหรับ matrix ขนาดใหญ่มาก วิธีการ Krylov subspace อาจให้ eigenvalue ประมาณภายในความคลาดเคลื่อนที่ต้องการได้เร็วกว่า diagonalization algorithm แบบดั้งเดิม
- สำหรับ matrix ขนาดใหญ่มากดังกล่าว การสร้าง Krylov subspace คือส่วนที่ใช้เวลามากที่สุดของวิธีการ Krylov subspace
- ดังนั้นวิธีที่มีประสิทธิภาพในการสร้าง Krylov subspace จะมีคุณค่าอย่างยิ่ง นี่คือจุดที่คอมพิวเตอร์ควอนตัมเข้ามามีบทบาทในที่สุด
ทดสอบความเข้าใจ
อ่านคำถามด้านล่าง คิดคำตอบ แล้วคลิกสามเหลี่ยมเพื่อดูคำตอบ
ดูกราฟ smooth ของเวลาทแยงมุมเทียบกับมิติของ matrix ข้างต้น
(a) ที่มิติของ matrix ประมาณเท่าใดที่วิธีการ Krylov เร็วกว่า ตามกราฟนี้?
(b) ปัจจัยใดบ้างที่อาจเปลี่ยนมิตินั้นที่วิธีการ Krylov เร็วกว่า?
คำตอบ:
(a) คำตอบอาจแตกต่างกันถ้ารันการคำนวณซ้ำ แต่วิธีการ Krylov เร็วกว่าที่มิติประมาณ 80-85 (b) มีคำตอบที่เป็นไปได้มากมาย ปัจจัยสำคัญบางอย่าง ได้แก่ ความแม่นยำที่ต้องการและความเบาบางของ matrix ที่ทแยงมุม
3. Krylov ผ่าน time evolution
ทุกสิ่งที่เราอธิบายมาจนถึงตอนนี้สามารถทำได้แบบคลาสสิก แล้วเมื่อใดและอย่างไรจึงจะใช้คอมพิวเตอร์ควอนตัม? สำหรับ matrix ขนาดใหญ่มาก วิธีการ Krylov อาจต้องใช้เวลาคำนวณนานและหน่วยความจำจำนวนมาก เวลาที่ใช้สำหรับการดำเนินการ matrix ของ บน ปรับขนาดเหมือน ในกรณีเลวร้ายที่สุด แม้แต่การคูณ matrix เบาบางกับเวกเตอร์ (กรณีทั่วไปสำหรับ Krylov solver แบบคลาสสิก) มีความซับซ้อนของเวลาปรับขนาดเหมือน ซึ่งทำสำหรับทุกเวกเตอร์ที่ต้องการใน subspace มิติ subspace มักไม่ใช่สัดส่วนสำคัญของ และมักปรับขนาดเหมือน ดังนั้นการสร้างเวกเตอร์ทั้งหมดปรับขนาดเหมือน ในกรณีเลวร้ายที่สุด แม้จะมีขั้นตอนอื่น เช่น orthogonalization แต่นี่คือการปรับขนาดหลักที่ควรนึกถึง
การคำนวณเชิงควอนตัมช่วยให้เราเปลี่ยนคุณลักษณะของปัญหาที่กำหนดการปรับขนาดของเวลาและทรัพยากรที่ใช้ แทนที่จะพึ่งพาขนาด matrix ทุกที่ เราจะเห็นสิ่งต่างๆ เช่น จำนวน shots และจำนวน Pauli terms ที่ไม่สับเปลี่ยนกันที่ประกอบ Hamiltonian มาสำรวจว่าสิ่งนี้ทำงานอย่างไร
3.1 Time evolution
จำว่า operator ที่ evolve สถานะควอนตัมตามเวลาคือ (เป็นเรื่องปกติมากโดยเฉพาะในการคำนวณเชิงควอนตัมที่จะละ จากสัญลักษณ์) วิธีหนึ่งในการเข้าใจและแม้แต่ realize ฟังก์ชัน exponential ของ operator คือมองที่การขยาย Taylor series สังเกตว่าการดำเนินการนี้กับเวกเตอร์เริ่มต้น ให้ผลรวมของ terms ที่มี กำลังสูงขึ้นดำเนินการบนสถานะเริ่มต้น ดูเหมือนเราสามารถสร้าง Krylov subspace โดยการ time-evolve สถานะการเดาเริ่มต้น!
ข้อแม้คือการ realize time evolution บนคอมพิวเตอร์ควอนตัมจริง term หลายตัวใน Hamiltonian จะไม่สับเปลี่ยนกัน ดังนั้นในขณะที่ exponential operator บางอย่างเช่น สอดคล้องกับ circuit ง่ายๆ Hamiltonian ทั่วไปไม่เป็นเช่นนั้น และเนื่องจากมี terms ที่ไม่สับเปลี่ยนกัน เราไม่สามารถแยก exponential ออกเป็นผลคูณของ exponential ง่ายๆ ได้ เหมือนที่ทำกับตัวเลข
ดังนั้นสิ่งนี้ไม่ใช่เรื่องง่าย แต่เป็นกระบวนการที่ศึกษากันอย่างกว้างขวางในการคำนวณเชิงควอนตัม เราทำ time evolution บนคอมพิวเตอร์ควอนตัมโดยใช้กระบวนการที่เรียกว่า trotterization ซึ่งเป็นหัวข้อที่มีเนื้อหาสมบูรณ์ในตัวเอง[10] แต่ในระดับสูงมาก โดยการแบ่ง time evolution ออกเป็น steps เล็กมาก สมมติว่า steps ขนาด เราจำกัดผลกระทบของการไม่สับเปลี่ยนกันของ terms
โดยที่
ให้เรียก Krylov subspace อันดับ r ที่สร้างในบริบทคลาสสิกโดยใช้กำลังของ H โดยตรงว่า "power Krylov subspace"
ตอนนี้สร้าง space ที่คล้ายกันโดยใช้ unitary time-evolution operator เรียกว่า "unitary Krylov space" power Krylov subspace ที่เราใช้แบบคลาสสิกไม่สามารถสร้างโดยตรงบนคอมพิวเตอร์ควอนตัมเพราะ ไม่ใช่ unitary operator การใช้ unitary Krylov subspace สามารถแสดงได้ว่าให้การรับประกันการลู่เข้าที่คล้ายกับ power Krylov subspace กล่าวคือ ground state error ลู่เข้าอย่างมีประสิทธิภาพตราบเท่าที่สถานะเริ่มต้น มี overlap กับ ground state จริงที่ไม่ลดลงแบบ exponential และตราบเท่าที่มี gap เพียงพอระหว่าง eigenvalue ดู Ref [1] สำหรับการอภิปรายเรื่องการลู่เข้าที่แม่นยำกว่า
ที่นี่ กำลังของ กลายเป็น time steps ที่แตกต่างกัน (กำลังที่ ของ คือการก้าวไปข้างหน้าด้วยเวลา ) เราสามารถระบุ element ของ subspace ที่ time-evolve ไปเวลาทั้งหมด ว่า
เราสามารถฉาย Hamiltonian H ลงใน unitary Krylov subspace กล่าวอีกนัยหนึ่ง คำนวณ matrix element แต่ละตัวของ ใน basis เราจะเรียก projected matrix นี้ว่า
3.2 วิธี implement บนคอมพิวเตอร์ควอนตัม
Matrix element ของ กำหนดโดย expectation values ซึ่งสามารถประมาณโดยใช้คอมพิวเตอร์ควอนตัม จำว่า สามารถเขียนเป็นผลรวมของ Pauli operators บน Qubit ต่างๆ และไม่ใช่ทุก Pauli operator จะสามารถวัดพร้อมกันได้ เราสามารถจัด Pauli terms เป็นกลุ่มของ terms ที่สับเปลี่ยนกันและวัดทั้งหมดพร้อมกัน แต่อาจต้องใช้กลุ่มดังกล่าวหลายกลุ่มเพื่อครอบคลุม terms ทั้งหมด ดังนั้นจำนวนกลุ่มการสับเปลี่ยนที่แยกกันที่ terms สามารถแบ่งได้ จึงมีความสำคัญ
ที่นี่ คือ Pauli string ในรูปแบบ หรือชุดของ Pauli string ดังกล่าวที่สับเปลี่ยนกัน เมื่อเราเขียน เป็นผลรวมของ measurable operators ดังกล่าว สูตรต่อไปนี้สำหรับ matrix element ของ สามารถ realize ได้โดยใช้ Qiskit Runtime primitive Estimator
โดยที่ คือเวกเตอร์ของ unitary Krylov space และ คือผลคูณของ time step ที่เลือก บนคอมพิวเตอร์ควอนตัม การคำนวณ matrix element แต่ละตัวสามารถทำได้ด้วย algorithm ใดๆ ที่ช่วยให้ได้ overlap ระหว่าง quantum state ในบทเรียนนี้เราจะเน้นที่ Hadamard test เมื่อ มีมิติ Hamiltonian ที่ฉายลงใน subspace จะมีมิติ เมื่อ เล็กพอ (โดยทั่วไป เพียงพอสำหรับการลู่เข้าของการประมาณ eigenvalue) เราสามารถทแยงมุม projected Hamiltonian แบบคลาสสิกได้ง่าย อย่างไรก็ตาม เราไม่สามารถทแยงมุม โดยตรงได้เพราะ Krylov space vectors ไม่ตั้งฉากซึ่งกันและกัน เราต้องวัด overlaps และสร้าง matrix
สิ่งนี้ช่วยให้เราแก้ปัญหา eigenvalue ใน space ที่ไม่ตั้งฉาก (เรียกอีกอย่างว่า generalized eigenvalue problem)
จากนั้นสามารถหาการประมาณของ eigenvalue และ eigenstate ของ ได้โดยดูที่ผลลัพธ์ของ generalized eigenvalue problem นี้ ตัวอย่างเช่น การประมาณพลังงาน ground state ได้จากการหา eigenvalue ต่ำสุด และ ground state จาก eigenvector ที่สอดคล้องกัน สัมประสิทธิ์ใน กำหนดการมีส่วนร่วมของเวกเตอร์ต่างๆ ที่ขึง
Generalized eigenvalue problem
ทำไมเราไม่สามารถทแยงมุม โดยตรงได้? เนื่องจาก มีข้อมูลเกี่ยวกับเรขาคณิตของ Krylov basis (ซึ่งไม่ตั้งฉากในทุกกรณียกเว้นกรณีพิเศษมาก) โดยลำพังไม่ได้อธิบายการฉายของ full Hamiltonian ดังนั้น eigenvalue ของมันไม่มีความสัมพันธ์เฉพาะกับของ full Hamiltonian และอาจเป็นค่าสุ่มใดๆ การแก้ generalized eigenvalue problem จำเป็นต้องหา eigenvalue และ eigenvector ประมาณที่สอดคล้องกับการฉายของ full Hamiltonian เข้าสู่ Krylov space
ภาพแสดงการแสดง circuit ของ modified Hadamard test ซึ่งเป็นวิธีที่ใช้คำนวณ overlap ระหว่าง quantum state ต่างๆ สำหรับแต่ละ matrix element จะทำ Hadamard test ระหว่าง state , สิ่งนี้เน้นด้วยรูปแบบสีสำหรับ matrix element และการดำเนินการ , ที่สอดคล้องกัน ดังนั้นต้องทำ Hadamard test ชุดหนึ่งสำหรับ combination ที่เป็นไปได้ทั้งหมดของ Krylov space vectors เพื่อคำนวณ matrix element ทั้งหมดของ projected Hamiltonian สาย wire บนสุดใน Hadamard test circuit คือ ancilla qubit ที่วัดใน X หรือ Y basis ค่า expectation ของมันกำหนดค่า overlap ระหว่าง state สาย wire ล่างแทน Qubit ทั้งหมดของ system Hamiltonian การดำเนินการ เตรียม system qubit ใน state ที่ควบคุมโดย state ของ ancilla qubit (เช่นเดียวกันสำหรับ ) และการดำเนินการ แทน Pauli decomposition ของ system Hamiltonian การ implement นี้บนคอมพิวเตอร์ควอนตัมแสดงอย่างละเอียดกว่าด้านล่าง
4. การทแยงมุมแบบควอนตัม Krylov บนคอมพิวเตอร์ควอนตัม
ตอนนี้เราจะ implement Krylov quantum diagonalization บนคอมพิวเตอร์ควอนตัมจริง มาเริ่มด้วยการนำเข้า package ที่มีประโยชน์
import numpy as np
import scipy as sp
import matplotlib.pylab as plt
from typing import Union, List
import warnings
from qiskit.quantum_info import SparsePauliOp, Pauli
from qiskit.circuit import Parameter
from qiskit import QuantumCircuit, QuantumRegister
from qiskit.circuit.library import PauliEvolutionGate
from qiskit.synthesis import LieTrotter
# from qiskit.providers.fake_provider import Fake20QV1
from qiskit_ibm_runtime import QiskitRuntimeService, EstimatorV2 as Estimator, Batch
import itertools as it
warnings.filterwarnings("ignore")
นิยามฟังก์ชันด้านล่างเพื่อแก้ generalized eigenvalue problem ที่อธิบายข้างต้น
def solve_regularized_gen_eig(
h: np.ndarray,
s: np.ndarray,
threshold: float,
k: int = 1,
return_dimn: bool = False,
) -> Union[float, List[float]]:
"""
Method for solving the generalized eigenvalue problem with regularization
Args:
h (numpy.ndarray):
The effective representation of the matrix in our Krylov subspace
s (numpy.ndarray):
The matrix of overlaps between vectors of our Krylov subspace
threshold (float):
Cut-off value for the eigenvalue of s
k (int):
Number of eigenvalues to return
return_dimn (bool):
Whether to return the size of the regularized subspace
Returns:
lowest k-eigenvalue(s) that are the solution of the regularized generalized eigenvalue problem
"""
s_vals, s_vecs = sp.linalg.eigh(s)
s_vecs = s_vecs.T
good_vecs = np.array([vec for val, vec in zip(s_vals, s_vecs) if val > threshold])
h_reg = good_vecs.conj() @ h @ good_vecs.T
s_reg = good_vecs.conj() @ s @ good_vecs.T
if k == 1:
if return_dimn:
return sp.linalg.eigh(h_reg, s_reg)[0][0], len(good_vecs)
else:
return sp.linalg.eigh(h_reg, s_reg)[0][0]
else:
if return_dimn:
return sp.linalg.eigh(h_reg, s_reg)[0][:k], len(good_vecs)
else:
return sp.linalg.eigh(h_reg, s_reg)[0][:k]
อย่างน้อยในการ benchmark เริ่มต้น เป็นประโยชน์ที่รู้คำตอบคลาสสิกที่แน่นอนเพื่อตรวจสอบพฤติกรรมการลู่เข้า ฟังก์ชันด้านล่างคำนวณพลังงาน ground state ของ Hamiltonian โดยใช้ Hamiltonian และจำนวน Qubit เป็น arguments
def single_particle_gs(H_op, n_qubits):
"""
Find the ground state of the single particle(excitation) sector
"""
H_x = []
for p, coeff in H_op.to_list():
H_x.append(set([i for i, v in enumerate(Pauli(p).x) if v]))
H_z = []
for p, coeff in H_op.to_list():
H_z.append(set([i for i, v in enumerate(Pauli(p).z) if v]))
H_c = H_op.coeffs
print("n_sys_qubits", n_qubits)
n_exc = 1
sub_dimn = int(sp.special.comb(n_qubits + 1, n_exc))
print("n_exc", n_exc, ", subspace dimension", sub_dimn)
few_particle_H = np.zeros((sub_dimn, sub_dimn), dtype=complex)
sparse_vecs = [
set(vec) for vec in it.combinations(range(n_qubits + 1), r=n_exc)
] # list all of the possible sets of n_exc indices of 1s in n_exc-particle states
m = 0
for i, i_set in enumerate(sparse_vecs):
for j, j_set in enumerate(sparse_vecs):
m += 1
if len(i_set.symmetric_difference(j_set)) <= 2:
for p_x, p_z, coeff in zip(H_x, H_z, H_c):
if i_set.symmetric_difference(j_set) == p_x:
sgn = ((-1j) ** len(p_x.intersection(p_z))) * (
(-1) ** len(i_set.intersection(p_z))
)
else:
sgn = 0
few_particle_H[i, j] += sgn * coeff
gs_en = min(np.linalg.eigvalsh(few_particle_H))
print("single particle ground state energy: ", gs_en)
return gs_en
4.1 ขั้นตอนที่ 1: แมปปัญหาไปยัง quantum circuit และ operator
ตอนนี้เราจะนิยาม Hamiltonian สิ่งนี้แตกต่างจากฟังก์ชันข้างต้น ตรงที่ฟังก์ชันข้างต้นรับ Hamiltonian เป็น argument และคืนเฉพาะ ground state แบบคลาสสิก Hamiltonian ที่นิยามที่นี่กำหนดระดับพลังงานของ energy eigenstate ทั้งหมด และสามารถสร้างโดยใช้ Pauli operators และ implement บนคอมพิวเตอร์ควอนตัมได้
เราเลือก Hamiltonian ที่สอดคล้องกับ chain ของ spin ที่สามารถหันได้ทุกทิศทางในอวกาศ เรียกว่า "Heisenberg chain" เราสมมติว่า spin ที่ ได้รับอิทธิพลจากเพื่อนบ้านที่ใกล้ที่สุด (spin ที่ และ ) แต่ไม่ใช่จากเพื่อนบ้านที่ไกลกว่า นอกจากนี้เราอนุญาตให้ interaction ระหว่าง spin แตกต่างกันเมื่อ spin ชี้ไปในแกนต่างๆ ความไม่สมมาตรนี้บางครั้งเกิดขึ้น เช่น เนื่องจากโครงสร้างของ crystal lattice ที่ spin ฝังอยู่
# Define problem Hamiltonian.
n_qubits = 10
# coupling strength for XX, YY, and ZZ interactions
JX = 1
JY = 3
JZ = 2
# Define the Hamiltonian:
H_int = [["I"] * n_qubits for _ in range(3 * (n_qubits - 1))]
for i in range(n_qubits - 1):
H_int[i][i] = "Z"
H_int[i][i + 1] = "Z"
for i in range(n_qubits - 1):
H_int[n_qubits - 1 + i][i] = "X"
H_int[n_qubits - 1 + i][i + 1] = "X"
for i in range(n_qubits - 1):
H_int[2 * (n_qubits - 1) + i][i] = "Y"
H_int[2 * (n_qubits - 1) + i][i + 1] = "Y"
H_int = ["".join(term) for term in H_int]
H_tot = [
(term, JZ)
if term.count("Z") == 2
else (term, JY)
if term.count("Y") == 2
else (term, JX)
for term in H_int
]
# Get operator
H_op = SparsePauliOp.from_list(H_tot)
print(H_tot)
[('ZZIIIIIIII', 2), ('IZZIIIIIII', 2), ('IIZZIIIIII', 2), ('IIIZZIIIII', 2), ('IIIIZZIIII', 2), ('IIIIIZZIII', 2), ('IIIIIIZZII', 2), ('IIIIIIIZZI', 2), ('IIIIIIIIZZ', 2), ('XXIIIIIIII', 1), ('IXXIIIIIII', 1), ('IIXXIIIIII', 1), ('IIIXXIIIII', 1), ('IIIIXXIIII', 1), ('IIIIIXXIII', 1), ('IIIIIIXXII', 1), ('IIIIIIIXXI', 1), ('IIIIIIIIXX', 1), ('YYIIIIIIII', 3), ('IYYIIIIIII', 3), ('IIYYIIIIII', 3), ('IIIYYIIIII', 3), ('IIIIYYIIII', 3), ('IIIIIYYIII', 3), ('IIIIIIYYII', 3), ('IIIIIIIYYI', 3), ('IIIIIIIIYY', 3)]
โค้ดด้านล่างจำกัด Hamiltonian ให้อยู่ใน single particle states และใช้ spectral norm เพื่อกำหนดขนาดที่เหมาะสมสำหรับ time step เราเลือกค่า dt แบบ heuristic (โดยอิงจาก upper bounds ของ Hamiltonian norm) Ref [9] แสดงว่า time step ที่เล็กพอคือ และควรประมาณค่าต่ำกว่าดีกว่าประมาณค่าสูงกว่า เพราะการประมาณค่าสูงกว่าทำให้ contribution จาก high-energy states ทำให้สถานะที่ดีที่สุดใน Krylov space เสียหาย ในทางกลับกัน การเลือก เล็กเกินไปทำให้ conditioning ของ Krylov subspace แย่ลง เพราะ Krylov basis vectors แตกต่างกันน้อยลงในแต่ละ timestep
# Get Hamiltonian restricted to single-particle states
single_particle_H = np.zeros((n_qubits, n_qubits))
for i in range(n_qubits):
for j in range(i + 1):
for p, coeff in H_op.to_list():
p_x = Pauli(p).x
p_z = Pauli(p).z
if all(p_x[k] == ((i == k) + (j == k)) % 2 for k in range(n_qubits)):
sgn = ((-1j) ** sum(p_z[k] and p_x[k] for k in range(n_qubits))) * (
(-1) ** p_z[i]
)
else:
sgn = 0
single_particle_H[i, j] += sgn * coeff
for i in range(n_qubits):
for j in range(i + 1, n_qubits):
single_particle_H[i, j] = np.conj(single_particle_H[j, i])
# Set dt according to spectral norm
dt = np.pi / np.linalg.norm(single_particle_H, ord=2)
dt
np.float64(0.17453292519943295)
กำหนดมิติสูงสุดของ Krylov ที่ต้องการใช้ แม้จะตรวจสอบการลู่เข้าที่มิติที่เล็กกว่า นอกจากนี้กำหนดจำนวน Trotter steps ที่ใช้ใน time evolution เพื่อบทเรียนนี้ เราจะเลือกมิติ Krylov เล็กเพียง 5 ซึ่งค่อนข้างจำกัดในบริบทของแอปพลิเคชันจริง แต่เพียงพอสำหรับตัวอย่างนี้ เราจะสำรวจวิธีการในบทเรียนต่อๆ มาที่ช่วยให้ปรับขนาดและฉาย Hamiltonian ลงใน subspace ที่ใหญ่กว่า
# Set parameters for quantum Krylov algorithm
krylov_dim = 4 # size of krylov subspace
num_trotter_steps = 4
dt_circ = dt / num_trotter_steps
การเตรียม State
เลือก reference state ที่มี overlap กับ ground state สำหรับ Hamiltonian นี้ เราใช้ state ที่มี excitation ใน qubit กลาง เป็น reference state ของเรา
qc_state_prep = QuantumCircuit(n_qubits)
qc_state_prep.x(int(n_qubits / 2) + 1)
qc_state_prep.draw("mpl", scale=0.5)

Time evolution
เราสามารถ realize time-evolution operator ที่สร้างโดย Hamiltonian ที่กำหนด: ผ่าน Lie-Trotter approximation เพื่อความเรียบง่าย เราใช้ PauliEvolutionGate ที่มีอยู่แล้วใน time-evolution circuit syntax ทั่วไปคือ
t = Parameter("t")
## Create the time-evo op circuit
evol_gate = PauliEvolutionGate(
H_op, time=t, synthesis=LieTrotter(reps=num_trotter_steps)
)
qr = QuantumRegister(n_qubits)
qc_evol = QuantumCircuit(qr)
qc_evol.append(evol_gate, qargs=qr)
<qiskit.circuit.instructionset.InstructionSet at 0x7ccaa4664250>
เราจะใช้เวอร์ชันนี้ด้านล่างใน Hadamard test โดยก้าวไปข้างหน้าทีละ
Hadamard test
จำว่าเราต้องการคำนวณ matrix element ของทั้ง และ Gram matrix โดยใช้ Hadamard test มาทบทวนวิธีการทำงานในบริบทนี้ โดยเน้นที่การสร้าง ก่อน กระบวนการโดยรวมแสดงเป็นกราฟิกด้านล่าง layer ของบล็อกเตรียม state สี เตือนว่ากระบวนการนี้ทำสำหรับ combination ทั้งหมดของ และ ใน subspace
สถานะของ system ที่ขั้นตอนที่ระบุคือ:
ที่นี่ คือ Pauli term ในการ decomposition ของ Hamiltonian (สังเกตว่าไม่สามารถเป็น linear combination ของ Pauli terms ที่สับเปลี่ยนกันหลายตัว เพราะจะไม่ใช่ unitary การจัดกลุ่มเป็นไปได้โดยใช้การสร้างที่แตกต่างกันซึ่งจะแสดงภายหลัง) , คือการดำเนินการที่ควบคุมซึ่งเตรียม , vectors ของ unitary Krylov space โดยที่ การวัด และ กับ circuit นี้คำนวณส่วน real และ imaginary ตามลำดับ ของ matrix element ที่ต้องการ
เริ่มจาก Step 4 ข้างต้น ใช้ Hadamard gate กับ qubit ที่ศูนย์
จากนั้นวัด หรือ
จาก identity เช่นเดียวกัน การวัด ให้
เพิ่ม steps เหล่านี้ใน time evolution ที่ตั้งค่าไว้ก่อนหน้า เขียนดังต่อไปนี้
## Create the time-evo op circuit
evol_gate = PauliEvolutionGate(
H_op, time=dt, synthesis=LieTrotter(reps=num_trotter_steps)
)
## Create the time-evo op dagger circuit
evol_gate_d = PauliEvolutionGate(
H_op, time=dt, synthesis=LieTrotter(reps=num_trotter_steps)
)
evol_gate_d = evol_gate_d.inverse()
# Put pieces together
qc_reg = QuantumRegister(n_qubits)
qc_temp = QuantumCircuit(qc_reg)
qc_temp.compose(qc_state_prep, inplace=True)
for _ in range(num_trotter_steps):
qc_temp.append(evol_gate, qargs=qc_reg)
for _ in range(num_trotter_steps):
qc_temp.append(evol_gate_d, qargs=qc_reg)
qc_temp.compose(qc_state_prep.inverse(), inplace=True)
# Create controlled version of the circuit
controlled_U = qc_temp.to_gate().control(1)
# Create hadamard test circuit for real part
qr = QuantumRegister(n_qubits + 1)
qc_real = QuantumCircuit(qr)
qc_real.h(0)
qc_real.append(controlled_U, list(range(n_qubits + 1)))
qc_real.h(0)
print("Circuit for calculating the real part of the overlap in S via Hadamard test")
qc_real.draw("mpl", fold=-1, scale=0.5)
Circuit for calculating the real part of the overlap in S via Hadamard test

เราได้เตือนแล้วเกี่ยวกับความลึกที่เกี่ยวข้องกับ Trotter circuits การทำ Hadamard test ในสภาพเหล่านี้อาจให้ circuit ที่ลึกยิ่งขึ้น โดยเฉพาะเมื่อ decompose เป็น native gates สิ่งนี้จะเพิ่มขึ้นอีกหากคำนึงถึง topology ของ device ดังนั้นก่อนใช้เวลาบนคอมพิวเตอร์ควอนตัม ควรตรวจสอบ 2-qubit depth ของ circuit
print(
"Number of layers of 2Q operations",
qc_real.decompose(reps=2).depth(lambda x: x[0].num_qubits == 2),
)
Number of layers of 2Q operations 14401
Circuit ที่มีความลึกนี้ไม่สามารถให้ผลลัพธ์ที่ใช้งานได้บนคอมพิวเตอร์ควอนตัมยุคใหม่ ถ้าจะสร้าง และ เราต้องการวิธีที่ดีกว่า นี่คือเหตุผลของ efficient Hadamard test ที่แนะนำด้านล่าง
4. 2 ขั้นตอนที่ 2. ปรับ circuit และ operator สำหรับ hardware เป้าหมาย
Efficient Hadamard test
เราสามารถ optimize circuit ที่ลึกสำหรับ Hadamard test ที่ได้โดยนำ approximation มาใช้และอาศัยสมมติฐานบางอย่างเกี่ยวกับ Hamiltonian ของโมเดล ตัวอย่างเช่น พิจารณา circuit ต่อไปนี้สำหรับ Hadamard test:
สมมติว่าเราสามารถคำนวณ แบบคลาสสิกได้ ซึ่งเป็น eigenvalue ของ ภายใต้ Hamiltonian สิ่งนี้เป็นไปตามเมื่อ Hamiltonian รักษา U(1) symmetry แม้ดูเหมือนเป็นสมมติฐานที่แข็งแกร่ง แต่มีหลายกรณีที่ปลอดภัยที่จะสมมติว่ามี vacuum state (ในกรณีนี้แมปไปยัง state) ที่ไม่ได้รับผลกระทบจากการดำเนินการของ Hamiltonian สิ่งนี้เป็นจริงเช่นสำหรับ chemistry Hamiltonians ที่อธิบาย stable molecule (ที่จำนวน electron ได้รับการอนุรักษ์) เมื่อ gate เตรียม reference state ที่ต้องการ ตัวอย่างเช่น เพื่อเตรียม HF state สำหรับ chemistry จะเป็น product ของ single-qubit NOT ดังนั้น controlled- คือ product ของ CNOT จากนั้น circuit ข้างต้น implement สถานะต่อไปนี้ก่อนการวัด:
โดยใช้ phase shift ที่คำนวณแบบคลาสสิกได้ จาก step 2 ถึง 3 ดังนั้น expectation values คือ
โดยใช้สมมติฐานเหล่านี้ เราสามารถเขียน expectation values ของ operators ที่สนใจด้วย controlled operations ที่น้อยลง ที่จริงแล้วเราต้องการ implement controlled state preparation เท่านั้น ไม่ใช่ controlled time evolutions การกำหนดกรอบการคำนวณใหม่ดังข้างต้นจะช่วยให้เราลดความลึกของ circuit ผลลัพธ์ได้อย่างมาก
สังเกตว่าเป็น bonus เนื่องจาก Pauli operator ปรากฏเป็นการวัดที่ท้าย circuit แทนที่จะเป็น controlled gate ตรงกลาง จึงสามารถวัดพร้อมกับ Pauli operators อื่นที่สับเปลี่ยนกันได้ดังใน decomposition ที่กล่าวไว้ข้างต้น
Decompose time-evolution operator ด้วย Trotter decomposition
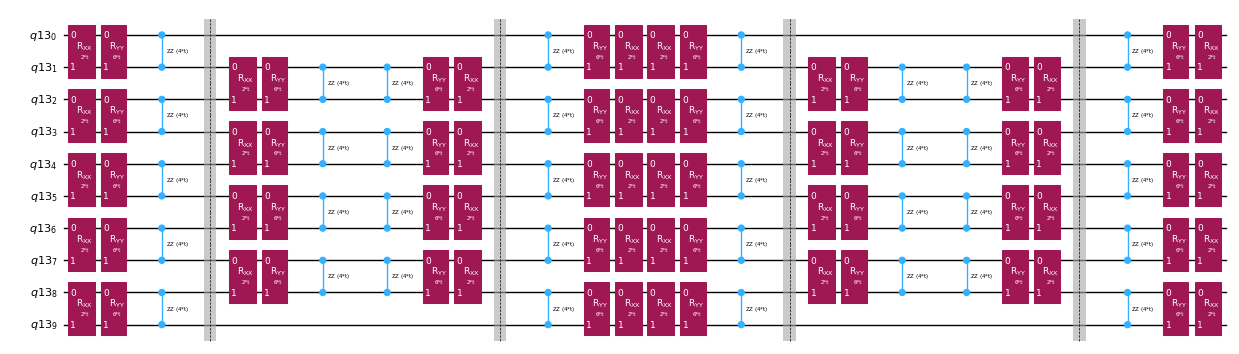
แทนที่จะ implement time-evolution operator อย่างแม่นยำ เราสามารถใช้ Trotter decomposition เพื่อ implement การประมาณของมัน การทำซ้ำ Trotter decomposition อันดับหนึ่งหลายครั้งช่วยลด error จาก approximation เพิ่มเติม ในต่อไปนี้ เราสร้าง Trotter implementation โดยตรงในวิธีที่มีประสิทธิภาพที่สุดสำหรับ interaction graph ของ Hamiltonian ที่พิจารณา (nearest neighbor interactions เท่านั้น) ในทางปฏิบัติเราแทรก Pauli rotations , , ที่มีมุม parameter t ซึ่งสอดคล้องกับการ implement ประมาณของ เมื่อพิจารณาความแตกต่างในนิยามของ Pauli rotations และ time evolution ที่เราพยายาม implement เราต้องใช้ parameter 2*dt เพื่อให้ได้ time evolution ของ dt นอกจากนี้เราพลิกลำดับของการดำเนินการสำหรับ Trotter steps จำนวนคี่ ซึ่งเทียบเท่ากันทางฟังก์ชัน แต่ช่วยให้ synthesize การดำเนินการที่อยู่ติดกันเป็น unitary เดียว ทำให้ได้ circuit ที่ตื้นกว่ามากเมื่อเทียบกับที่ได้โดยใช้ PauliEvolutionGate() ทั่วไป
t = Parameter("t")
# Create instruction for rotation about XX+YY-ZZ:
Rxyz_circ = QuantumCircuit(2)
Rxyz_circ.rxx(2 * JX * t, 0, 1)
Rxyz_circ.ryy(2 * JY * t, 0, 1)
Rxyz_circ.rzz(2 * JZ * t, 0, 1)
Rxyz_instr = Rxyz_circ.to_instruction(label="R J_x XX + J_y YY + J_z ZZ")
interaction_list = [
[[i, i + 1] for i in range(0, n_qubits - 1, 2)],
[[i, i + 1] for i in range(1, n_qubits - 1, 2)],
] # linear chain
qr = QuantumRegister(n_qubits)
trotter_step_circ = QuantumCircuit(qr)
for i, color in enumerate(interaction_list):
for interaction in color:
trotter_step_circ.append(Rxyz_instr, interaction)
if i < len(interaction_list) - 1:
trotter_step_circ.barrier()
reverse_trotter_step_circ = trotter_step_circ.reverse_ops()
qc_evol = QuantumCircuit(qr)
for step in range(num_trotter_steps):
if step % 2 == 0:
qc_evol = qc_evol.compose(trotter_step_circ)
else:
qc_evol = qc_evol.compose(reverse_trotter_step_circ)
qc_evol.decompose().draw("mpl", fold=-1, scale=0.5)
เราเตรียม initial state อีกครั้งสำหรับ efficient Hadamard test นี้
control = 0
excitation = int(n_qubits / 2) + 1
controlled_state_prep = QuantumCircuit(n_qubits + 1)
controlled_state_prep.cx(control, excitation)
controlled_state_prep.draw("mpl", fold=-1, scale=0.5)

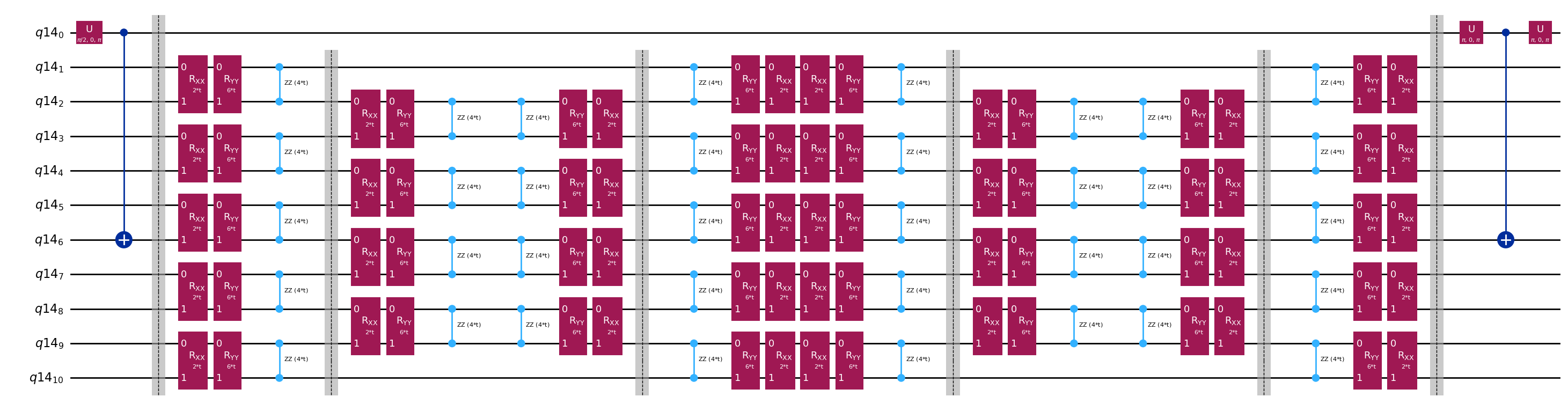
Template circuits สำหรับคำนวณ matrix element ของ และ ผ่าน Hadamard test
ความแตกต่างเดียวระหว่าง circuit ที่ใช้ใน Hadamard test คือ phase ใน time-evolution operator และ observable ที่วัด ดังนั้นเราสามารถเตรียม template circuit ที่แสดง circuit ทั่วไปสำหรับ Hadamard test พร้อม placeholder สำหรับ gate ที่ขึ้นกับ time-evolution operator
# Parameters for the template circuits
parameters = []
for idx in range(1, krylov_dim):
parameters.append(dt_circ * (idx))
# Create modified hadamard test circuit
qr = QuantumRegister(n_qubits + 1)
qc = QuantumCircuit(qr)
qc.h(0)
qc.compose(controlled_state_prep, list(range(n_qubits + 1)), inplace=True)
qc.barrier()
qc.compose(qc_evol, list(range(1, n_qubits + 1)), inplace=True)
qc.barrier()
qc.x(0)
qc.compose(controlled_state_prep.inverse(), list(range(n_qubits + 1)), inplace=True)
qc.x(0)
qc.decompose().draw("mpl", fold=-1)
print(
"The optimized circuit has 2Q gates depth: ",
qc.decompose().decompose().depth(lambda x: x[0].num_qubits == 2),
)
The optimized circuit has 2Q gates depth: 50
ความลึกนี้ลดลงอย่างมากเมื่อเทียบกับ Hadamard test ต้นฉบับ ความลึกนี้สามารถจัดการได้บนคอมพิวเตอร์ควอนตัมยุคใหม่ แม้ยังค่อนข้างสูง เราจะต้องใช้ error mitigation ที่ล้ำที่สุดเพื่อให้ได้ผลลัพธ์ที่ใช้งานได้
เลือก backend สำหรับ run การคำนวณ Krylov แบบควอนตัม เพื่อให้เราสามารถ transpile circuit สำหรับ run บนคอมพิวเตอร์ควอนตัมนั้น
# Use the least-busy backend or specify a quantum computer using the syntax commented out below.
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
# Or you may choose a specify backend and channel if necessary for your workflow.
# service = QiskitRuntimeService(channel="ibm_quantum_platform")
# backend = service.backend("ibm_fez")
ตอนนี้ transpile circuit และ operator
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
target = backend.target
basis_gates = list(target.operation_names)
pm = generate_preset_pass_manager(
optimization_level=3, backend=backend, basis_gates=basis_gates
)
qc_trans = pm.run(qc)
print(qc_trans.depth(lambda x: x[0].num_qubits == 2))
print(qc_trans.count_ops())
qc_trans.draw("mpl", fold=-1, idle_wires=False, scale=0.5)
36
OrderedDict([('rz', 410), ('sx', 361), ('cz', 156), ('x', 18), ('barrier', 6)])

หลัง optimization ความลึก two-qubit ของ transpiled circuit ลดลงอีก
4.3 ขั้นตอนที่ 3. Execute โดยใช้ Qiskit Runtime primitive
ตอนนี้สร้าง PUB สำหรับ execute ด้วย Estimator
# Define observables to measure for S
observable_S_real = "I" * (n_qubits) + "X"
observable_S_imag = "I" * (n_qubits) + "Y"
observable_op_real = SparsePauliOp(
observable_S_real
) # define a sparse pauli operator for the observable
observable_op_imag = SparsePauliOp(observable_S_imag)
layout = qc_trans.layout # get layout of transpiled circuit
observable_op_real = observable_op_real.apply_layout(
layout
) # apply physical layout to the observable
observable_op_imag = observable_op_imag.apply_layout(layout)
observable_S_real = (
observable_op_real.paulis.to_labels()
) # get the label of the physical observable
observable_S_imag = observable_op_imag.paulis.to_labels()
observables_S = [[observable_S_real], [observable_S_imag]]
# Define observables to measure for H
# Hamiltonian terms to measure
observable_list = []
for pauli, coeff in zip(H_op.paulis, H_op.coeffs):
# print(pauli)
observable_H_real = pauli[::-1].to_label() + "X"
observable_H_imag = pauli[::-1].to_label() + "Y"
observable_list.append([observable_H_real])
observable_list.append([observable_H_imag])
layout = qc_trans.layout
observable_trans_list = []
for observable in observable_list:
observable_op = SparsePauliOp(observable)
observable_op = observable_op.apply_layout(layout)
observable_trans_list.append([observable_op.paulis.to_labels()])
observables_H = observable_trans_list
# Define a sweep over parameter values
params = np.vstack(parameters).T
# Estimate the expectation value for all combinations of
# observables and parameter values, where the pub result will have
# shape (# observables, # parameter values).
pub = (qc_trans, observables_S + observables_H, params)
Circuit สำหรับ สามารถคำนวณแบบคลาสสิกได้ เราทำสิ่งนี้ก่อนไปยังกรณี โดยใช้คอมพิวเตอร์ควอนตัม
from qiskit.quantum_info import StabilizerState, Pauli
qc_cliff = qc.assign_parameters({t: 0})
# Get expectation values from experiment
S_expval_real = StabilizerState(qc_cliff).expectation_value(
Pauli("I" * (n_qubits) + "X")
)
S_expval_imag = StabilizerState(qc_cliff).expectation_value(
Pauli("I" * (n_qubits) + "Y")
)
# Get expectation values
S_expval = S_expval_real + 1j * S_expval_imag
H_expval = 0
for obs_idx, (pauli, coeff) in enumerate(zip(H_op.paulis, H_op.coeffs)):
# Get expectation values from experiment
expval_real = StabilizerState(qc_cliff).expectation_value(
Pauli(pauli[::-1].to_label() + "X")
)
expval_imag = StabilizerState(qc_cliff).expectation_value(
Pauli(pauli[::-1].to_label() + "Y")
)
expval = expval_real + 1j * expval_imag
# Fill-in matrix elements
H_expval += coeff * expval
print(H_expval)
(10+0j)
แม้จะลดความลึกของ gate ลงได้หลายอันดับความใหญ่โดยใช้ efficient Hadamard test แต่ความลึกยังเพียงพอที่ต้องการ error mitigation ล้ำ ด้านล่างระบุคุณลักษณะของ mitigation ที่ใช้ วิธีการทั้งหมดที่ใช้มีความสำคัญ แต่ควรกล่าวถึง probabilistic error amplification (PEA) เป็นพิเศษ เทคนิคอันทรงพลังนี้มี quantum overhead มาก การคำนวณที่ทำที่นี่อาจใช้เวลา 20 นาทีหรือมากกว่าบนคอมพิวเตอร์ควอนตัมจริง คุณอาจต้องการปรับ parameter ด้านล่างเพื่อเพิ่มหรือลดความแม่นยำและ overhead ที่ตามมา การตั้งค่า default ด้านล่างให้ผลลัพธ์ที่มี fidelity สูง
# Experiment options
num_randomizations = 300
num_randomizations_learning = 20
max_batch_circuits = 20
shots_per_randomization = 100
learning_pair_depths = [0, 4, 24]
noise_factors = [1, 1.3, 1.6]
# Base option formatting
options = {
# Builtin resilience settings for ZNE
"resilience": {
"measure_mitigation": True,
"zne_mitigation": True,
"zne": {"noise_factors": noise_factors},
# TREX noise learning configuration
"measure_noise_learning": {
"num_randomizations": num_randomizations_learning,
"shots_per_randomization": shots_per_randomization,
},
# PEA noise model configuration
"layer_noise_learning": {
"max_layers_to_learn": 10,
"layer_pair_depths": learning_pair_depths,
"shots_per_randomization": shots_per_randomization,
"num_randomizations": num_randomizations_learning,
},
},
# Randomization configuration
"twirling": {
"num_randomizations": num_randomizations,
"shots_per_randomization": shots_per_randomization,
"strategy": "all",
},
# Experimental settings for PEA method
"experimental": {
# # Just in case, disable any further qiskit transpilation not related to twirling / DD
# "skip_transpilation": True,
# Execution configuration
"execution": {
"max_pubs_per_batch_job": max_batch_circuits,
"fast_parametric_update": True,
},
# Error Mitigation configuration
"resilience": {
# ZNE Configuration
"zne": {
"amplifier": "pea",
"return_all_extrapolated": True,
"return_unextrapolated": True,
"extrapolated_noise_factors": [0] + noise_factors,
}
},
},
}
สุดท้าย execute circuit สำหรับ และ ด้วย Estimator
# This job required 17 minutes of QPU time to run on a Heron r2 processor. This is only an estimate.
# Your execution time may vary.
with Batch(backend=backend) as batch:
# Estimator
estimator = Estimator(mode=batch, options=options)
job = estimator.run([pub], precision=1)
4.4 ขั้นตอนที่ 4. Post-process และวิเคราะห์ผลลัพธ์
สิ่งที่เราได้จากคอมพิวเตอร์ควอนตัมคือ matrix element แต่ละตัวของ และกลุ่ม Pauli ที่สับเปลี่ยนกันซึ่งประกอบ matrix element ของ terms เหล่านี้ต้องรวมกันเพื่อกู้คืน matrix เพื่อที่เราจะแก้ generalized eigenvalue problem ได้
# Store the outputs as 'results'.
results = job.result()[0]
คำนวณ Effective Hamiltonian และ Overlap matrices
ขั้นแรกคำนวณ phase ที่สะสมโดย state ระหว่าง uncontrolled time evolution
prefactors = [
np.exp(-1j * sum([c for p, c in H_op.to_list() if "Z" in p]) * i * dt)
for i in range(1, krylov_dim)
]
เมื่อได้ผลลัพธ์ของการ execute circuit แล้ว เราสามารถ post-process ข้อมูลเพื่อคำนวณ matrix element ของ
# Assemble S, the overlap matrix of dimension D:
S_first_row = np.zeros(krylov_dim, dtype=complex)
S_first_row[0] = 1 + 0j
# Add in ancilla-only measurements:
for i in range(krylov_dim - 1):
# Get expectation values from experiment
expval_real = results.data.evs[0][0][i] # automatic extrapolated evs if ZNE is used
expval_imag = results.data.evs[1][0][i] # automatic extrapolated evs if ZNE is used
# Get expectation values
expval = expval_real + 1j * expval_imag
S_first_row[i + 1] += prefactors[i] * expval
S_first_row_list = S_first_row.tolist() # for saving purposes
S_circ = np.zeros((krylov_dim, krylov_dim), dtype=complex)
# Distribute entries from first row across matrix:
for i, j in it.product(range(krylov_dim), repeat=2):
if i >= j:
S_circ[j, i] = S_first_row[i - j]
else:
S_circ[j, i] = np.conj(S_first_row[j - i])
from sympy import Matrix
Matrix(S_circ)
และ matrix element ของ
import itertools
# Assemble S, the overlap matrix of dimension D:
H_first_row = np.zeros(krylov_dim, dtype=complex)
H_first_row[0] = H_expval
for obs_idx, (pauli, coeff) in enumerate(zip(H_op.paulis, H_op.coeffs)):
# Add in ancilla-only measurements:
for i in range(krylov_dim - 1):
# Get expectation values from experiment
expval_real = results.data.evs[2 + 2 * obs_idx][0][
i
] # automatic extrapolated evs if ZNE is used
expval_imag = results.data.evs[2 + 2 * obs_idx + 1][0][
i
] # automatic extrapolated evs if ZNE is used
# Get expectation values
expval = expval_real + 1j * expval_imag
H_first_row[i + 1] += prefactors[i] * coeff * expval
H_first_row_list = H_first_row.tolist()
H_eff_circ = np.zeros((krylov_dim, krylov_dim), dtype=complex)
# Distribute entries from first row across matrix:
for i, j in itertools.product(range(krylov_dim), repeat=2):
if i >= j:
H_eff_circ[j, i] = H_first_row[i - j]
else:
H_eff_circ[j, i] = np.conj(H_first_row[j - i])
from sympy import Matrix
Matrix(H_eff_circ)
สุดท้าย เราสามารถแก้ generalized eigenvalue problem สำหรับ :
และได้การประมาณพลังงาน ground state
gnd_en_circ_est_list = []
for d in range(1, krylov_dim + 1):
# Solve generalized eigenvalue problem
gnd_en_circ_est = solve_regularized_gen_eig(
H_eff_circ[:d, :d], S_circ[:d, :d], threshold=1e-1
)
gnd_en_circ_est_list.append(gnd_en_circ_est)
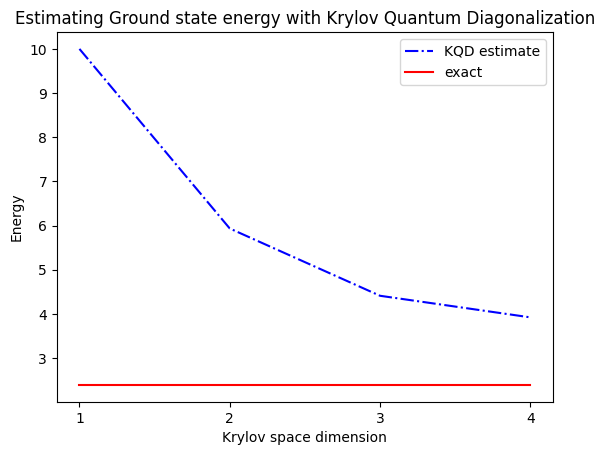
print("The estimated ground state energy is: ", gnd_en_circ_est)
The estimated ground state energy is: 10.0
The estimated ground state energy is: 5.933953916292923
The estimated ground state energy is: 4.4101773995740645
The estimated ground state energy is: 3.921288588521255
สำหรับ single-particle sector เราสามารถคำนวณ ground state ของ sector นี้ของ Hamiltonian แบบคลาสสิกได้อย่างมีประสิทธิภาพ
gs_en = single_particle_gs(H_op, n_qubits)
n_sys_qubits 10
n_exc 1 , subspace dimension 11
single particle ground state energy: 2.391547869638771
len(H_op)
27
plt.plot(
range(1, krylov_dim + 1),
gnd_en_circ_est_list,
color="blue",
linestyle="-.",
label="KQD estimate",
)
plt.plot(
range(1, krylov_dim + 1),
[gs_en] * krylov_dim,
color="red",
linestyle="-",
label="exact",
)
plt.xticks(range(1, krylov_dim + 1), range(1, krylov_dim + 1))
plt.legend()
plt.xlabel("Krylov space dimension")
plt.ylabel("Energy")
plt.title("Estimating Ground state energy with Krylov Quantum Diagonalization")
plt.show()
5. การอภิปรายและการขยาย
สรุปคือ เราเริ่มจาก reference state จากนั้น evolve มันในช่วงเวลาต่างๆ เพื่อสร้าง unitary Krylov subspace เราฉาย Hamiltonian ลงใน subspace นั้น นอกจากนี้เราประมาณ overlaps ของ subspace vectors สุดท้ายเราแก้ generalized eigenvalue problem ที่มีมิติต่ำกว่าแบบคลาสสิก
มาเปรียบเทียบว่าอะไรกำหนดค่าใช้จ่ายในการคำนวณของการใช้เทคนิค Krylov แบบคลาสสิกและเชิงควอนตัม ไม่มี analog ที่สมบูรณ์แบบระหว่างแนวทางคลาสสิกและควอนตัมในทุกขั้นตอน ตารางนี้รวบรวมการปรับขนาดของขั้นตอนต่างๆ เพื่อพิจารณา
จำว่า Hamiltonian โดยทั่วไปมี terms ที่ไม่สามารถวัดพร้อมกันได้ (เพราะไม่สับเปลี่ยนซึ่งกันและกัน) เราจัด terms ใน Hamiltonian เป็นกลุ่มของ Pauli operators ที่สับเปลี่ยนกันซึ่งสามารถวัดพร้อมกันได้ทั้งหมด และเราอาจต้องการกลุ่มดังกล่าวหลายกลุ่มเพื่อครอบคลุม terms ทั้งหมดที่ไม่สับเปลี่ยนซึ่งกันและกัน การสร้าง บนคอมพิวเตอร์ควอนตัมต้องการการวัดแยกต่างหากสำหรับแต่ละกลุ่มของ Pauli strings ที่สับเปลี่ยนกันใน Hamiltonian และแต่ละกลุ่มต้องการ shots หลายครั้ง เราต้องทำสิ่งนี้สำหรับ matrix element ที่แตกต่างกัน ตัว ที่สอดคล้องกับ combination ที่แตกต่างกัน ของ time evolution factors บางครั้งมีวิธีลดสิ่งนี้ แต่ใน treatment คร่าวๆ นี้ เวลาที่ใช้ปรับขนาดเหมือน element ของ ต้องประมาณ ปรับขนาดเหมือน สุดท้าย การแก้ generalized eigenvalue problem ใน projected space แบบคลาสสิก ใช้เวลา
เราเห็นว่าการทแยงมุมแบบควอนตัม Krylov อาจมีประโยชน์ในกรณีที่จำนวนกลุ่ม Pauli ที่สับเปลี่ยนกันใน Hamiltonian ค่อนข้างน้อย การพึ่งพาการปรับขนาดเหล่านี้บ่งชี้แอปพลิเคชันบางอย่างที่วิธีการ Krylov มีประโยชน์ และแอปพลิเคชันอื่นที่น่าจะไม่เป็นประโยชน์ Hamiltonian บางตัวมีความซับซ้อนสูงเมื่อแมปไปยัง Qubit เกี่ยวข้องกับ Pauli strings ที่ไม่สับเปลี่ยนกันจำนวนมากซึ่งไม่สามารถแบ่งออกเป็นกลุ่มที่สับเปลี่ยนกันได้ง่าย มักเป็นจริงสำหรับปัญหา quantum chemistry ตัวอย่างเช่น ความซับซ้อนนี้สร้างความท้าทายหลักสองประการสำหรับคอมพิวเตอร์ควอนตัมยุคใกล้:
- การประมาณของแต่ละ element ของ มีค่าใช้จ่ายการคำนวณสูงเนื่องจาก terms จำนวนมาก
- Trotter circuits ที่ต้องการลึกจนไม่สามารถใช้งานได้จริง
ทั้งสองประเด็นข้างต้นจะปัญหาน้อยลงเมื่อคอมพิวเตอร์ควอนตัมถึง fault-tolerance แต่ต้องพิจารณาในระยะใกล้ แม้แต่ระบบที่มีการแมปง่ายกว่าใน quantum chemistry อาจพบอุปสรรคเดียวกัน หาก Hamiltonian มี terms ที่ไม่สับเปลี่ยนกันมากเกินไป วิธีการ Krylov มีประโยชน์ที่สุดเมื่อ Hamiltonian สามารถแบ่งออกเป็นกลุ่ม Pauli ที่สับเปลี่ยนกันค่อนข้างน้อย และ ง่ายต่อการ implement ใน trotter circuits ทั้งสองเงื่อนไขนี้เป็นที่พอใจ เช่น สำหรับ lattice models หลายตัวที่น่าสนใจในฟิสิกส์ KQD มีประโยชน์เป็นพิเศษหากทราบน้อยมากเกี่ยวกับ ground state สิ่งนี้มาจากการรับประกันการลู่เข้าที่มีอยู่ในตัวและการใช้ได้ในสถานการณ์ที่วิธีการทางเลือกไม่สามารถทำได้เนื่องจากความรู้เกี่ยวกับ ground state ไม่เพียงพอ
แม้ KQD จะเป็นเครื่องมืออันทรงพลัง แต่ด้านที่ใช้เวลานานของ protocol โดยเฉพาะการประมาณของแต่ละ element ของ projected Hamiltonian และ overlap ของ Krylov states แสดงถึงโอกาสในการปรับปรุง แนวทางทางเลือกเกี่ยวข้องกับการใช้ประโยชน์จากวิธีการ Krylov ร่วมกับวิธีการที่อิงการสุ่มตัวอย่าง ซึ่งเป็นหัวข้อของบทเรียนถัดไป
6. ภาคผนวก
ภาคผนวก I: Krylov subspace จาก real time-evolutions
unitary Krylov space นิยามเป็น
สำหรับ timestep บางค่าที่เราจะกำหนดภายหลัง สมมติชั่วคราวว่า เป็นคู่: นิยาม สังเกตว่าเมื่อเราฉาย Hamiltonian เข้าสู่ Krylov space ข้างต้น มันแยกไม่ออกจาก Krylov space
คือที่ time-evolutions ทั้งหมดถูก shift ไปข้างหลัง timesteps เหตุผลที่แยกไม่ออกคือ matrix element
ไม่เปลี่ยนแปลงภายใต้การ shift เวลา evolution โดยรวม เนื่องจาก time-evolutions สับเปลี่ยนกับ Hamiltonian สำหรับ คี่ เราใช้การวิเคราะห์สำหรับ
เราต้องการแสดงว่าที่ไหนสักแห่งใน Krylov space นี้ มีการรับประกันว่าจะมี low-energy state เราทำเช่นนี้โดยใช้ผลลัพธ์ต่อไปนี้ ซึ่งมาจาก Theorem 3.1 ใน [3]:
อ้างสิทธิ์ 1: มีฟังก์ชัน อยู่ เช่นว่าสำหรับพลังงาน ในช่วง spectral ของ Hamiltonian (คือระหว่างพลังงาน ground state และพลังงานสูงสุด)...
- สำหรับค่า ทั้งหมดที่อยู่ห่าง จาก คือถูก suppress แบบ exponential
- คือ linear combination ของ สำหรับ
เราให้การพิสูจน์ด้านล่าง แต่สามารถข้ามไปได้อย่างปลอดภัยยกเว้นต้องการเข้าใจ argument เต็มรูปแบบอย่างเข้มงวด ตอนนี้เน้นที่นัยสำคัญของ claim ข้างต้น โดยคุณสมบัติ 3 ข้างต้น เราเห็นว่า Krylov space ที่ shift แล้วข้างต้นมี state นี่คือ low-energy state ของเรา เพื่อดูว่าทำไม เขียน ใน energy eigenbasis:
โดยที่ คือ energy eigenstate ลำดับ k และ คือ amplitude ของมันใน initial state ในแง่นี้ คือ
โดยใช้ข้อเท็จจริงว่าเราสามารถแทน ด้วย เมื่อดำเนินการบน eigenstate energy error ของ state นี้จึงเป็น
เพื่อเปลี่ยนสิ่งนี้เป็น upper bound ที่เข้าใจง่ายขึ้น ขั้นแรกแยกผลรวมในตัวเศษออกเป็น terms ที่ และ terms ที่ :
เราสามารถ upper bound term แรกด้วย ,
โดยที่ขั้นตอนแรกเป็นเพราะ สำหรับทุก ในผลรวม และขั้นตอนที่สองเป็นเพราะผลรวมในตัวเศษเป็น subset ของผลรวมในตัวส่วน สำหรับ term ที่สอง ขั้นแรก lower bound ตัวส่วนด้วย เนื่องจาก : รวมทุกอย่างกลับเข้าด้วยกัน จะได้
เพื่อทำให้สิ่งที่เหลืออยู่ง่ายขึ้น สังเกตว่าสำหรับ เหล่านี้ทั้งหมด โดยนิยามของ เราทราบว่า นอกจากนี้ upper bound และ upper bound ให้
สิ่งนี้เป็นจริงสำหรับ ใดๆ ดังนั้นถ้าเราตั้งค่า เท่ากับ error เป้าหมาย upper bound ของ error ข้างต้นจะลู่เข้าสู่ error นั้นแบบ exponential ตาม Krylov dimension นอกจากนี้สังเกตว่าถ้า แล้ว term จะหายไปในขอบเขตข้างต้นทั้งหมด
เพื่อให้ argument สมบูรณ์ ขั้นแรกสังเกตว่าข้างต้นเป็นเพียง energy error ของ state เฉพาะ ไม่ใช่ energy error ของ state พลังงานต่ำสุดใน Krylov space อย่างไรก็ตาม โดย (Rayleigh-Ritz) variational principle energy error ของ state พลังงานต่ำสุดใน Krylov space ถูก upper bound โดย energy error ของ state ใดๆ ใน Krylov space ดังนั้นข้างต้นก็เป็น upper bound ของ energy error ของ state พลังงานต่ำสุดด้วย คือ output ของ Krylov quantum diagonalization algorithm
การวิเคราะห์คล้ายกับข้างต้นสามารถทำได้ที่คำนึงถึง noise และขั้นตอน thresholding ที่อภิปรายใน notebook ด้วย ดู [2] และ [4] สำหรับการวิเคราะห์นี้
ภาคผนวก II: การพิสูจน์อ้างสิทธิ์ 1
ต่อไปนี้อิงมากจาก [3], Theorem 3.1: ให้ และ เป็น space ของ residual polynomials (polynomials ที่มีค่าที่ 0 เท่ากับ 1) ของดีกรีไม่เกิน คำตอบของ
คือ
และค่า minimal ที่สอดคล้องกันคือ
เราต้องการแปลงสิ่งนี้เป็นฟังก์ชันที่สามารถแสดงได้อย่างเป็นธรรมชาติในรูปแบบ complex exponentials เพราะนั่นคือ real time-evolutions ที่สร้าง quantum Krylov space เพื่อทำเช่นนั้น สะดวกที่จะนำ transformation ต่อไปนี้ของพลังงานภายใน spectral range ของ Hamiltonian ไปยังตัวเลขในช่วง : นิยาม
โดยที่ คือ timestep เช่นว่า สังเกตว่า และ เพิ่มขึ้นเมื่อ เคลื่อนออกจาก
ตอนนี้โดยใช้ polynomial ด้วย parameters a, b, d ตั้งค่าเป็น , , และ d = int(r/2) เรานิยามฟังก์ชัน:
โดยที่ คือพลังงาน ground state เราเห็นได้โดยแทน ว่า คือ trigonometric polynomial ดีกรี คือ linear combination ของ สำหรับ นอกจากนี้ จากนิยามของ ข้างต้น เราได้ว่า และสำหรับ ใดๆ ใน spectral range เช่นว่า เราได้
อ้างอิง:
[1] https://arxiv.org/abs/2407.14431
[2] https://arxiv.org/abs/1811.09025
[3] https://people.math.ethz.ch/~mhg/pub/biksm.pdf
[4] https://academic.oup.com/book/36426
[5] https://en.wikipedia.org/wiki/Krylov_subspace
[6] Krylov Subspace Methods: Principles and Analysis, Jörg Liesen, Zdenek Strakos https://academic.oup.com/book/36426
[7] Iterative Methods for Sparse Linear Systems" by Yousef Saad
[8] "MINRES-QLP: A Krylov Subspace Method for Indefinite or Singular Symmetric Systems" by Sou-Cheng Choi, Christopher Paige, and Michael Saunders (https://epubs.siam.org/doi/10.1137/100787921)
[9] Ethan N. Epperly, Lin Lin, and Yuji Nakatsukasa. "A theory of quantum subspace diagonalization". SIAM Journal on Matrix Analysis and Applications 43, 1263–1290 (2022).