The variational quantum eigensolver (VQE)
บทเรียนนี้จะแนะนำ variational quantum eigensolver อธิบายความสำคัญในฐานะอัลกอริทึมพื้นฐานในควอนตัมคอมพิวติ้ง และสำรวจจุดแข็งและจุดอ่อนของมัน VQE โดยตัวมันเองโดยไม่มีวิธีเสริม อาจไม่เพียงพอสำหรับการคำนวณควอนตัมระดับ utility scale ในปัจจุบัน แม้กระนั้น มันมีความสำคัญในฐานะวิธีไฮบริดคลาสสิก-ควอนตัมต้นแบบ และเป็นรากฐานสำคัญที่อัลกอริทึมขั้นสูงกว่าหลายตัวถูกสร้างขึ้น
วิดีโอนี้ให้ภาพรวมของ VQE และปัจจัยที่ส่งผลต่อประสิทธิภาพ ข้อความด้านล่างเพิ่มรายละเอียดและนำ VQE ไปใช้งานด้วย Qiskit
1. VQE คืออะไร?
variational quantum eigensolver เป็นอัลกอริทึมที่ใช้การคำนวณแบบคลาสสิกและควอนตัมร่วมกันเพื่อทำงาน มีองค์ประกอบหลักสี่ส่วนของการคำนวณ VQE:
- ตัวดำเนินการ: มักจะเป็น Hamiltonian ที่เราเรียกว่า ซึ่งอธิบายคุณสมบัติของระบบที่ต้องการ optimize อีกวิธีพูดคือ เรากำลังหา eigenvector ของตัวดำเนินการนี้ที่สอดคล้องกับ eigenvalue ต่ำสุด เรามักเรียก eigenvector นั้นว่า "ground state"
- "ansatz" (คำเยอรมันแปลว่า "แนวทาง"): คือ quantum circuit ที่เตรียม quantum state ที่ประมาณ eigenvector ที่ต้องการ จริงๆ แล้ว ansatz คือกลุ่มของ quantum circuit เนื่องจาก gate บางตัวใน ansatz ถูก parameterize กล่าวคือ ถูกป้อนพารามิเตอร์ที่เราสามารถเปลี่ยนได้ กลุ่ม quantum circuit นี้สามารถเตรียมกลุ่ม quantum state ที่ประมาณ ground state ได้
- Estimator: วิธีการประมาณค่าความคาดหวังของตัวดำเนินการ บน variational quantum state ปัจจุบัน บางครั้งสิ่งที่เราต้องการจริงๆ คือค่าความคาดหวังนี้ ซึ่งเราเรียกว่า cost function บางครั้ง เราสนใจฟังก์ชันที่ซับซ้อนกว่าซึ่งยังสามารถเขียนได้จากค่าความคาดหวังหนึ่งหรือหลายค่า
- Classical optimizer: อัลกอริทึมที่เปลี่ยนแปลงพารามิเตอร์เพื่อพยายาม minimize cost function
มาดูรายละเอียดของแต่ละองค์ประกอบเหล่านี้
1.1 ตัวดำเนินการ (Hamiltonian)
ที่หัวใจของปัญหา VQE คือตัวดำเนินการที่อธิบายระบบที่สนใจ เราจะสมมติว่า eigenvalue ต่ำสุดและ eigenvector ที่สอดคล้องของตัวดำเนินการนี้มีประโยชน์สำหรับวัตถุประสงค์ทางวิทยาศาสตร์หรือธุรกิจบางอย่าง ตัวอย่างอาจรวมถึง chemical Hamiltonian ที่อธิบายโมเลกุล โดยที่ eigenvalue ต่ำสุดของตัวดำเนินการสอดคล้องกับ ground state energy ของโมเลกุล และ eigenstate ที่สอดคล้องอธิบายรูปทรงหรือ electron configuration ของโมเลกุล หรือตัวดำเนินการอาจอธิบายต้นทุนของกระบวนการบางอย่างที่ต้องการ optimize และ eigenstate อาจสอดคล้องกับเส้นทางหรือแนวทางปฏิบัติ ในบางสาขาเช่นฟิสิกส์ "Hamiltonian" มักหมายถึงตัวดำเนินการที่อธิบายพลังงานของระบบกายภาพเสมอ แต่ในควอนตัมคอมพิวติ้ง เป็นเรื่องปกติที่จะเห็น quantum operator ที่อธิบายปัญหาธุรกิจหรือด้านโลจิสติกส์ถูกเรียกว่า "Hamiltonian" ด้วย เราจะนำแบบแผนนั้นมาใช้ที่นี่

การแมปปัญหากายภาพหรือการ optimization ไปยัง qubit มักเป็นงานที่ไม่ง่าย แต่รายละเอียดเหล่านั้นไม่ใช่จุดสนใจของ course นี้ การอภิปรายทั่วไปเกี่ยวกับการแมปปัญหาไปยัง quantum operator สามารถพบได้ใน Quantum computing in practice การมองที่ละเอียดขึ้นเกี่ยวกับการแมปปัญหาเคมีไปยัง quantum operator สามารถพบได้ใน Quantum Chemistry with VQE
สำหรับ course นี้ เราจะสมมติว่ารูปแบบของ Hamiltonian เป็นที่รู้จัก ตัวอย่างเช่น Hamiltonian สำหรับโมเลกุล hydrogen ง่ายๆ (ภายใต้สมมติฐาน active space บางอย่าง และใช้ Jordan-Wigner mapper) คือ:
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit qiskit-ibm-runtime scipy
from qiskit.quantum_info import SparsePauliOp
hamiltonian = SparsePauliOp(
[
"IIII",
"IIIZ",
"IZII",
"IIZI",
"ZIII",
"IZIZ",
"IIZZ",
"ZIIZ",
"IZZI",
"ZZII",
"ZIZI",
"YYYY",
"XXYY",
"YYXX",
"XXXX",
],
coeffs=[
-0.09820182 + 0.0j,
-0.1740751 + 0.0j,
-0.1740751 + 0.0j,
0.2242933 + 0.0j,
0.2242933 + 0.0j,
0.16891402 + 0.0j,
0.1210099 + 0.0j,
0.16631441 + 0.0j,
0.16631441 + 0.0j,
0.1210099 + 0.0j,
0.17504456 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
],
)
หมายเหตุว่าใน Hamiltonian ข้างต้น มี term เช่น ZZII และ YYYY ที่ไม่ commute กัน กล่าวคือ เพื่อประเมิน ZZII เราต้องวัด Pauli Z operator บน qubit 3 (รวมถึงการวัดอื่นๆ) แต่เพื่อประเมิน YYYY เราต้องวัด Pauli Y operator บน qubit เดียวกันนั้นคือ qubit 3 มีความสัมพันธ์ความไม่แน่นอนระหว่าง Y และ Z operator บน qubit เดียวกัน เราไม่สามารถวัด operator ทั้งสองนั้นพร้อมกันได้ เราจะกลับมาพูดถึงประเด็นนี้อีกครั้งด้านล่าง และตลอดทั้ง course
Hamiltonian ข้างต้นเป็น matrix operator ขนาด การ diagonalize ตัวดำเนินการเพื่อหา eigenvalue พลังงานต่ำสุดไม่ใช่เรื่องยาก
import numpy as np
A = np.array(hamiltonian)
eigenvalues, eigenvectors = np.linalg.eigh(A)
print("The ground state energy is ", min(eigenvalues), "hartrees")
The ground state energy is -1.1459778447627311 hartrees
classical eigensolver แบบ brute force ไม่สามารถขยายขนาดเพื่ออธิบายพลังงานหรือรูปทรงของระบบอะตอมขนาดใหญ่มากได้ เช่น ยา หรือ protein VQE เป็นหนึ่งในความพยายามแรกๆ ในการใช้ประโยชน์จากควอนตัมคอมพิวติ้งในปัญหานี้
เราจะพบ Hamiltonian ขนาดใหญ่กว่าข้างต้นมากในบทเรียนนี้ แต่คงไม่คุ้มค่าที่จะทดสอบขีดจำกัดของ VQE ก่อนที่เราจะแนะนำเครื่องมือขั้นสูงกว่าที่สามารถเสริมหรือทดแทน VQE ในภายหลังใน course นี้
1.2 Ansatz
คำว่า "ansatz" เป็นภาษาเยอรมันแปลว่า "แนวทาง" รูปพหูพจน์ที่ถูกต้องในภาษาเยอรมันคือ "ansätze" แม้ว่าจะมักเห็น "ansatzes" หรือ "ansatze" ด้วย ในบริบทของ VQE ansatz คือ quantum circuit ที่ใช้สร้าง multi-qubit wave function ที่ประมาณ ground state ของระบบที่ศึกษาได้ใกล้เคียงที่สุด และให้ค่าความคาดหวังของตัวดำเนินการที่ต่ำที่สุด quantum circuit นี้จะมีพารามิเตอร์แบบ variational (มักรวมกันในเวกเตอร์ของตัวแปร )

ค่าเริ่มต้น ของ variational parameter ถูกเลือก เราจะเรียก unitary operation ของ ansatz บน circuit ว่า โดยค่าเริ่มต้น qubit ทั้งหมดใน IBM® quantum computer จะถูก initialize เป็นสถานะ เมื่อรัน circuit สถานะของ qubit จะเป็น
ถ้าเราต้องการเพียงแค่พลังงานต่ำสุด (โดยใช้ภาษาของระบบกายภาพ) เราสามารถประมาณได้โดยเพียงแค่วัดพลังงานหลายครั้งและเลือกค่าต่ำสุด แต่โดยทั่วไปเรายังต้องการ configuration ที่ให้พลังงานหรือ eigenvalue ต่ำสุดนั้นด้วย ดังนั้นขั้นตอนต่อไปคือการประมาณค่าความคาดหวังของ Hamiltonian ซึ่งทำได้ผ่านการวัดควอนตัม มีหลายสิ่งที่เกี่ยวข้อง แต่เราสามารถเข้าใจกระบวนการนี้เชิงคุณภาพได้โดยสังเกตว่าความน่าจะเป็น ในการวัดพลังงาน (โดยใช้ภาษาของระบบกายภาพอีกครั้ง) สัมพันธ์กับค่าความคาดหวังโดย:
ความน่าจะเป็น ยังสัมพันธ์กับ overlap ระหว่าง eigenstate และสถานะปัจจุบันของระบบ :
ดังนั้น โดยการวัด Pauli operator ที่ประกอบ Hamiltonian ของเราหลายครั้ง เราสามารถประมาณค่าความคาดหวังของ Hamiltonian ในสถานะปัจจุบันของระบบ ขั้นตอนต่อไปคือการเปลี่ยนแปลงพารามิเตอร์ และพยายามเข้าใกล้สถานะ (ground) ที่มีพลังงานต่ำสุดของระบบ เนื่องจากพารามิเตอร์แบบ variational ใน ansatz บางครั้งจึงได้ยินเรียกมันว่า variational form
ก่อนที่เราจะไปสู่กระบวนการ variational นั้น หมายเหตุว่ามักเป็นประโยชน์ที่จะเริ่มต้น state ของคุณจากสถานะที่ "เดาได้ดี" คุณอาจรู้มากพอเกี่ยวกับระบบของคุณเพื่อทำการเดาเริ่มต้นที่ดีกว่า ตัวอย่างเช่น เป็นเรื่องปกติที่จะ initialize qubit ไปยัง Hartree-Fock state ในแอปพลิเคชันทางเคมี การเดาเริ่มต้นนี้ที่ไม่มีพารามิเตอร์แบบ variational เรียกว่า reference state เรียก quantum circuit ที่ใช้สร้าง reference state ว่า เมื่อใดก็ตามที่สำคัญที่จะแยก reference state ออกจาก ansatz ที่เหลือ ใช้: หรือเทียบเท่า
1.3 Estimator
เราต้องการวิธีประมาณค่าความคาดหวังของ Hamiltonian ใน variational state เฉพาะ ถ้าเราสามารถวัด operator ทั้งหมดโดยตรง สิ่งนี้จะง่ายพอๆ กับการวัดหลายครั้ง (สมมติว่า ) และหาค่าเฉลี่ยของค่าที่วัดได้:
ที่นี่ สัญลักษณ์ เตือนเราว่าค่าความคาดหวังนี้จะแม่นยำอย่างสมบูรณ์เฉพาะในขีดจำกัดที่ เท่านั้น แต่ด้วยการวัดหลายพัน sampling error ของค่าความคาดหวังค่อนข้างต่ำ มีข้อพิจารณาอื่นๆ เช่น noise ที่กลายเป็นปัญหาสำหรับการคำนวณที่แม่นยำมาก
อย่างไรก็ตาม โดยทั่วไปไม่สามารถวัด ได้ทั้งหมดในคราวเดียว อาจมี Pauli X, Y และ Z operator ที่ไม่ commute กันหลายตัว ดังนั้น Hamiltonian จึงต้องถูกแบ่งออกเป็นกลุ่มของ operator ที่สามารถวัดพร้อมกันได้ และกลุ่มดังกล่าวแต่ละกลุ่มต้องถูกประมาณแยกกัน และรวมผลลัพธ์เพื่อให้ได้ค่าความคาดหวัง เราจะกลับมาพูดถึงเรื่องนี้อย่างละเอียดมากขึ้นในบทเรียนถัดไปเมื่อเราอภิปรายการ scale ของวิธีคลาสสิกและควอนตัม ความซับซ้อนในการวัดนี้เป็นเหตุผลหนึ่งที่เราต้องการโค้ดที่มีประสิทธิภาพสูงสำหรับการประมาณดังกล่าว ในบทเรียนนี้และต่อๆ ไป เราจะใช้ Qiskit Runtime primitive Estimator สำหรับวัตถุประสงค์นี้
1.4 Classical optimizer
classical optimizer คืออัลกอริทึมคลาสสิกใดๆ ที่ออกแบบมาเพื่อหา extrema ของฟังก์ชันเป้าหมาย (โดยทั่วไปคือ minimum) มันค้นหาในปริภูมิของพารามิเตอร์ที่เป็นไปได้เพื่อหาชุดที่ minimize ฟังก์ชันที่สนใจ โดยกว้างๆ สามารถแบ่งได้เป็นวิธีที่ใช้ gradient ซึ่งใช้ข้อมูล gradient และวิธีที่ไม่ใช้ gradient ซึ่งทำงานเป็น black-box optimizer การเลือก classical optimizer อาจส่งผลกระทบอย่างมีนัยสำคัญต่อประสิทธิภาพของอัลกอริทึม โดยเฉพาะเมื่อมี noise ในฮาร์ดแวร์ควอนตัม optimizer ยอดนิยมในสาขานี้ได้แก่ Adam, AMSGrad และ SPSA ซึ่งแสดงผลลัพธ์ที่น่าสัญญาในสภาพแวดล้อมที่มี noise optimizer แบบดั้งเดิมได้แก่ COBYLA และ SLSQP
workflow ทั่วไป (สาธิตใน Section 3.3) คือการใช้อัลกอริทึมเหล่านี้เป็น method ภายใน minimizer เช่นฟังก์ชัน minimize ของ scipy ฟังก์ชันนี้รับ argument ต่อไปนี้:
- ฟังก์ชันบางอย่างที่ต้องการ minimize ซึ่งมักเป็นค่าความคาดหวังของพลังงาน แต่โดยทั่วไปเรียกว่า "cost function"
- ชุดพารามิเตอร์ที่จะเริ่มต้นค้นหา มักเรียกว่า หรือ
- Argument รวมถึง argument ของ cost function ในควอนตัมคอมพิวติ้งด้วย Qiskit argument เหล่านี้จะรวม ansatz, Hamiltonian และ Estimator primitive ซึ่งอภิปรายเพิ่มเติมใน subsection ถัดไป
- 'method' ของ minimization ซึ่งหมายถึงอัลกอริทึมเฉพาะที่ใช้ค้นหา parameter space นี่คือจุดที่เราจะระบุ เช่น COBYLA หรือ SLSQP
- Options ซึ่ง option ที่มีอาจแตกต่างกันตาม method แต่ตัวอย่างที่เกือบทุก method รวมไว้คือจำนวน iteration สูงสุดของ optimizer ก่อนสิ้นสุดการค้นหา: 'maxiter'

ในแต่ละขั้นตอน iterative ค่าความคาดหวังของ Hamiltonian จะถูกประมาณโดยการวัดหลายครั้ง พลังงานที่ประมาณได้นี้จะถูกส่งคืนโดย cost function และ minimizer จะอัปเดตข้อมูลที่มีเกี่ยวกับ energy landscape สิ่งที่ optimizer ทำเพื่อเลือกขั้นตอนต่อไปนั้นแตกต่างกันตาม method บางตัวใช้ gradient และเลือกทิศทางของ steepest descent บางตัวอาจคำนึงถึง noise และอาจกำหนดให้ cost ลดลงมากก่อนที่จะยอมรับว่าพลังงานที่แท้จริงลดลงตามทิศทางนั้น
# Example syntax for minimization
# from scipy.optimize import minimize
# res = minimize(cost_func, x0, args=(ansatz, hamiltonian, estimator), method="cobyla",
# options={'maxiter': 200})
1.5 หลักการ variational
ในบริบทนี้ variational principle มีความสำคัญมาก มันระบุว่า variational wave function ใดๆ ไม่สามารถให้ค่าความคาดหวังของพลังงาน (หรือ cost) ต่ำกว่าที่ ground state wave function ให้ได้ ในทางคณิตศาสตร์
สิ่งนี้ง่ายที่จะพิสูจน์ถ้าเราสังเกตว่าชุดของ eigenstate ทั้งหมด ของ ประกอบเป็น complete basis สำหรับ Hilbert space กล่าวอีกนัยหนึ่ง state ใดๆ และโดยเฉพาะ สามารถเขียนเป็นผลรวม weighted (normalized) ของ eigenstate เหล่านี้ของ :
โดยที่ เป็นค่าคงที่ที่ต้องกำหนด และ เราปล่อยให้เป็นแบบฝึกหัดสำหรับผู้อ่าน แต่สังเกต implication นี้: variational state ที่ให้ค่าความคาดหวังของพลังงานต่ำสุด คือ การประมาณ ground state ที่แท้จริงที่ดีที่สุด
ทดสอบความเข้าใจ
พิสูจน์ทางคณิตศาสตร์ว่า สำหรับ variational state ใดๆ
Answer
โดยใช้การกระจาย variational state ที่กำหนดในรูปของ energy eigenstate
เราสามารถเขียนค่าความคาดหวังของ variational energy ได้ว่า
สำหรับค่าสัมประสิทธิ์ทั้งหมด ดังนั้นเราสามารถเขียนได้ว่า
2. การเปรียบเทียบกับ workflow แบบคลาสสิก
สมมติว่าเราสนใจ matrix ที่มี N แถวและ N คอลัมน์ สมมติว่า matrix ของคุณใหญ่มากจนการ exact diagonalization ไม่ใช่ตัวเลือก สมมติต่อไปว่าคุณรู้เกี่ยวกับปัญหามากพอที่จะคาดเดาโครงสร้างโดยรวมของ target eigenstate และคุณต้องการสำรวจสถานะที่คล้ายกับการเดาเริ่มต้นของคุณเพื่อดูว่า cost/energy ของคุณสามารถลดลงได้อีกหรือไม่ นี่คือแนวทาง variational และเป็นวิธีหนึ่งที่ใช้เมื่อการ exact diagonalization ไม่ใช่ตัวเลือก
2.1 Classical workflow
โดยใช้คอมพิวเตอร์คลาสสิก นี่คือวิธีการทำงาน:
- สร้าง guess state พร้อมพารามิเตอร์ ที่จะเปลี่ยนแปลง: แม้ว่า guess เริ่มต้นนี้อาจเป็นแบบสุ่ม แต่นั่นไม่ใช่ที่แนะนำ เราต้องการใช้ความรู้เกี่ยวกับปัญหาเพื่อปรับ guess ของเราให้มากที่สุดเท่าที่เป็นไปได้
- คำนวณค่าความคาดหวังของ operator เมื่อระบบอยู่ในสถานะนั้น:
- เปลี่ยนแปลง variational parameter และทำซ้ำ:
- ใช้ข้อมูลสะสมเกี่ยวกับ landscape ของสถานะที่เป็นไปได้ใน variational subspace เพื่อทำการเดาที่ดีขึ้นเรื่อยๆ และเข้าใกล้ target state variational principle รับประกันว่า variational state ของเราไม่สามารถให้ eigenvalue ต่ำกว่า target ground state ดังนั้น ยิ่งค่าความคาดหวังต่ำลงเท่าไหร่ การประมาณ ground state ของเราก็ยิ่งดีขึ้นเท่านั้น:
มาพิจารณาความยากของแต่ละขั้นตอนในแนวทางนี้ การตั้งหรืออัปเดตพารามิเตอร์นั้นคำนวณได้ง่าย ความยากอยู่ที่การเลือกพารามิเตอร์เริ่มต้นที่มีประโยชน์และมีแรงบันดาลใจทางกายภาพ การใช้ข้อมูลสะสมจาก iteration ก่อนหน้าเพื่ออัปเดตพารามิเตอร์ในลักษณะที่เข้าใกล้ ground state ไม่ใช่เรื่องง่าย แต่มี classical optimization algorithm ที่ทำสิ่งนี้ได้อย่างมีประสิทธิภาพ classical optimization นี้มีต้นทุนสูงเฉพาะเพราะอาจต้องการ iteration จำนวนมาก ในกรณีที่แย่ที่สุด จำนวน iteration อาจ scale แบบ exponential กับ N ขั้นตอนเดี่ยวที่มีต้นทุนการคำนวณสูงที่สุดคือการคำนวณค่าความคาดหวังของ matrix โดยใช้ state ที่กำหนด :
matrix ขนาด ต้องกระทำบน vector ที่มี element ซึ่งสอดคล้องกับ: การคำนวณ multiplication ในกรณีที่แย่ที่สุด ต้องทำในแต่ละ iteration ของพารามิเตอร์ สำหรับ matrix ขนาดใหญ่มาก สิ่งนี้มีต้นทุนการคำนวณสูง
2.2 Quantum workflow และ commuting Pauli group
ลองจินตนาการถึงการมอบส่วนนี้ของการคำนวณให้คอมพิวเตอร์ควอนตัม แทนที่จะคำนวณค่าความคาดหวังนี้ คุณประมาณมันโดยการเตรียมสถานะ บนควอนตัมคอมพิวเตอร์โดยใช้ variational ansatz ของคุณ แล้วทำการวัด
นั่นอาจฟังดูง่ายกว่าที่เป็นจริง โดยทั่วไปวัดไม่ง่าย ตัวอย่างเช่น อาจประกอบด้วย Pauli X, Y และ Z operator ที่ไม่ commute กันหลายตัว แต่ สามารถ เขียนเป็น linear combination ของ term แต่ละตัวซึ่งวัดได้ง่าย (เช่น Pauli operator หรือกลุ่มของ Pauli operator ที่ commute กันแบบ qubit-wise) ค่าความคาดหวังของ บน state ใดๆ คือผลรวม weighted ของค่าความคาดหวังของ term ส่วนประกอบ นิพจน์นี้ใช้ได้สำหรับ state ใดๆ แต่เราจะใช้โดยเฉพาะกับ variational state ของเรา
โดยที่ คือ Pauli string เช่น IZZX…XIYX หรือ string หลายตัวที่ commute กัน ดังนั้นคำอธิบายของค่าความคาดหวังที่ใกล้เคียงกับความเป็นจริงของการวัดบนควอนตัมคอมพิวเตอร์มากขึ้นคือ
และในบริบทของ variational wave function ของเรา:
แต่ละ term สามารถวัดได้ ครั้ง ให้ measurement sample โดยที่ และส่งคืนค่าความคาดหวัง และ standard deviation เราสามารถรวม term เหล่านี้และ propagate error ผ่านผลรวมเพื่อให้ได้ค่าความคาดหวังรวม และ standard deviation
สิ่งนี้ไม่ต้องการการ multiplication ขนาดใหญ่ หรือกระบวนการใดๆ ที่จำเป็นต้อง scale เหมือน แต่ต้องการการวัดหลายครั้งบนควอนตัมคอมพิวเตอร์แทน ถ้าคุณไม่ต้องการมากเกินไป วิธีนี้อาจมีประสิทธิภาพ และนั่นคือส่วนควอนตัมของ VQE
แต่มาพูดถึงเหตุผลที่วิธีนี้อาจไม่มีประสิทธิภาพ เหตุผลหนึ่งสำหรับการวัดจำนวนมากคือการลด statistical uncertainty ในการประมาณ สำหรับการคำนวณที่ต้องการความแม่นยำสูง อีกเหตุผลคือจำนวน Pauli string ที่จำเป็นในการกาง matrix ทั้งหมดของคุณ เนื่องจาก Pauli matrix (บวก identity: X, Y, Z และ I) กาง space ของ operator ทั้งหมดของมิติที่กำหนด เราจึงรับประกันว่าสามารถเขียน matrix ที่สนใจของเราเป็น weighted sum ของ Pauli operator ได้เสมอ ดังที่ทำก่อนหน้านี้
โดยที่ คือ Pauli string ที่กระทำบน qubit ทั้งหมดที่อธิบายระบบของคุณ เช่น IZZX…XIYX หรือ string หลายตัวที่ commute กัน หมายเหตุว่า Qiskit ใช้ little endian notation โดยที่ Pauli operator ที่ จากด้านขวากระทำบน qubit ที่ ดังนั้นเราสามารถวัด operator ของเราได้โดยวัด Pauli operator ลำดับหนึ่ง
แต่เราไม่สามารถวัด Pauli operator ทั้งหมดนั้นพร้อมกันได้ Pauli operator (ยกเว้น I) ไม่ commute กันถ้าเกี่ยวข้องกับ qubit เดียวกัน ตัวอย่างเช่น เราสามารถวัด IZIZ และ ZZXZ พร้อมกันได้ เนื่องจากเราสามารถวัด I และ Z พร้อมกันสำหรับ qubit ที่สาม และเราสามารถรู้ I และ X พร้อมกันสำหรับ qubit ที่หนึ่ง แต่เราไม่สามารถวัด ZZZZ และ ZZZX พร้อมกันได้ เนื่องจาก Z และ X ไม่ commute กัน และทั้งคู่กระทำบน qubit ที่ 0 ผู้อ่านที่มีประสบการณ์อาจจำได้ว่าสอง group ของ Pauli operator อาจ commute กันในฐานะ set แม้ว่าการวัดของแต่ละ qubit แต่ละตัวจะไม่ commute กัน Estimator ถือว่าการวัด Pauli แบบ tensor-product (ผ่าน basis rotation) ซึ่งสอดคล้องกับการจัดกลุ่ม operator ที่เป็น qubit-wise commuting ดังนั้นเพื่อประมาณ string สอง string (A และ B) ของ Pauli operator พร้อมกันโดยใช้ Estimator Pauli operator ของแต่ละ qubit ใน A และ B จะต้อง commute กัน ซึ่งหมายความว่าเราไม่สามารถวัด ZZZZ และ ZZXX พร้อมกันด้วย

ดังนั้นเราจึง decompose matrix ของเราเป็นผลรวมของ Pauli ที่กระทำบน qubit ต่างๆ องค์ประกอบบางตัวของผลรวมนั้นสามารถวัดได้ทั้งหมดในคราวเดียว เราเรียกสิ่งนี้ว่า กลุ่มของ Pauli ที่ commute กัน ขึ้นอยู่กับว่ามี term ที่ไม่ commute กันมากแค่ไหน เราอาจต้องการกลุ่มดังกล่าวจำนวนมาก เรียกจำนวนของกลุ่ม Pauli string ที่ commute กันว่า ถ้า น้อย วิธีนี้อาจทำงานได้ดี ถ้า มีกลุ่มเป็นล้าน วิธีนี้จะไม่มีประโยชน์
กระบวนการที่จำเป็นสำหรับการประมาณค่าความคาดหวังถูกรวบรวมไว้ใน Qiskit Runtime primitive ที่เรียกว่า Estimator หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ Estimator ดู API reference ใน IBM Quantum® Documentation สามารถใช้ Estimator โดยตรงได้ แต่ Estimator ส่งคืนมากกว่าแค่ eigenvalue พลังงานต่ำสุด ตัวอย่างเช่น ยังส่งคืนข้อมูลเกี่ยวกับ ensemble standard error ด้วย ดังนั้น ในบริบทของปัญหา minimization มักเห็น Estimator ภายใน cost function หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ input และ output ของ Estimator ดู guide นี้บน IBM Quantum Documentation
คุณบันทึกค่าความคาดหวัง (หรือ cost function) สำหรับชุดพารามิเตอร์ ที่ใช้ใน state ของคุณ แล้วคุณอัปเดตพารามิเตอร์ เมื่อเวลาผ่านไป คุณสามารถใช้ค่าความคาดหวังหรือค่า cost function ที่ประมาณได้เพื่อประมาณ gradient ของ cost function ใน subspace ของสถานะที่สุ่มตัวอย่างโดย ansatz ของคุณ ทั้ง classical optimizer แบบ gradient-based และ gradient-free มีอยู่ ทั้งคู่ประสบกับปัญหาการเทรน เช่น local minima หลายตัว และพื้นที่ขนาดใหญ่ของ parameter space ที่มี gradient ใกล้ศูนย์ เรียกว่า barren plateau

2.3 ปัจจัยที่กำหนดต้นทุนการคำนวณ
VQE ไม่สามารถแก้ปัญหา quantum chemistry ที่ยากที่สุดทั้งหมดของคุณได้ แต่การดีขึ้นในการคำนวณทั้งหมดก็ไม่ใช่จุดประสงค์ เราได้เปลี่ยนสิ่งที่กำหนดต้นทุนการคำนวณ

เราได้เปลี่ยนจากกระบวนการที่ความซับซ้อนขึ้นอยู่กับมิติของ matrix เพียงอย่างเดียว ไปเป็นกระบวนการที่ขึ้นอยู่กับความแม่นยำที่ต้องการและจำนวน Pauli operator ที่ไม่ commute กันที่ประกอบ matrix ส่วนหลังไม่มี analog ในการคำนวณแบบคลาสสิก
ตาม dependency เหล่านี้ สำหรับ matrix แบบ sparse หรือ matrix ที่มี Pauli string ที่ไม่ commute กันน้อย กระบวนการนี้อาจมีประโยชน์ ซึ่งเป็นกรณีของระบบ spin ที่มีปฏิสัมพันธ์ เป็นต้น สำหรับ matrix แบบ dense อาจมีประโยชน์น้อยกว่า เรารู้ตัวอย่างเช่น ว่าระบบเคมีมักมี Hamiltonian ที่มี Pauli string หลายร้อย พัน หรือแม้กระทั่งล้านตัว มีงานวิจัยที่น่าสนใจเกี่ยวกับการลดจำนวน term เหล่านี้ แต่ระบบเคมีอาจเหมาะกว่าสำหรับอัลกอริทึมอื่นๆ ที่เราจะอภิปรายใน course นี้
ทดสอบความเข้าใจ
พิจารณา Hamiltonian บน qubit สี่ตัวที่มี term:
IIXX, IIXZ, IIZZ, IZXZ, IXXZ, ZZXZ, XZXZ, ZIXZ, ZZZZ, XXXX
คุณต้องการจัดกลุ่ม term เหล่านี้ให้ term ทั้งหมดในกลุ่มสามารถวัดพร้อมกันได้ จำนวนกลุ่มน้อยที่สุดที่สามารถทำได้โดยให้ครอบคลุม term ทั้งหมดคือเท่าไหร่?
Answer
สามารถทำได้ใน 4 กลุ่ม หมายเหตุว่าคำตอบดังกล่าวโดยทั่วไปไม่ unique
IIXX, XXXX, IIZZ, ZZZZ
IIXZ, IZXZ, ZIXZ, ZZXZ
IXXZ
XZXZ
อะไรที่คุณคาดว่าโดยทั่วไปทำให้ quantum chemistry ด้วย VQE ยาก: จำนวน term ใน Hamiltonian หรือการหา ansatz ที่ดี?
Answer
ปรากฎว่ามี ansatz ที่เพิ่มประสิทธิภาพสูงสำหรับบริบทเคมี จำนวน term ใน Hamiltonian และด้วยเหตุนี้จำนวนการวัดที่จำเป็นมักก่อให้เกิดปัญหามากกว่า
3. ตัวอย่าง Hamiltonian
มานำอัลกอริทึมนี้ไปใช้งานจริงโดยใช้ Hamiltonian matrix ขนาดเล็กเพื่อให้เราเห็นว่าเกิดอะไรขึ้นในแต่ละขั้นตอน เราจะใช้กรอบ Qiskit pattern:
-ขั้นตอนที่ 1: แมปปัญหาไปยัง quantum circuit และตัวดำเนินการ -ขั้นตอนที่ 2: เพิ่มประสิทธิภาพสำหรับฮาร์ดแวร์เป้าหมาย -ขั้นตอนที่ 3: รันบนฮาร์ดแวร์เป้าหมาย -ขั้นตอนที่ 4: Post-process ผลลัพธ์
3.1 ขั้นตอนที่ 1: แมปปัญหาไปยัง Quantum Circuit และตัวดำเนินการ
เราจะใช้ตัวที่นิยามข้างต้นจาก chemistry context เราเริ่มต้นด้วย general import บางตัว
# General imports
import numpy as np
# SciPy minimizer routine
from scipy.optimize import minimize
# Plotting functions
import matplotlib.pyplot as plt
อีกครั้ง เราสมมติว่า Hamiltonian ที่สนใจเป็นที่รู้จัก เราจะใช้ Hamiltonian ที่เล็กมากที่นี่ เนื่องจากวิธีอื่นๆ ที่อภิปรายใน course นี้จะมีประสิทธิภาพมากกว่าในการแก้ปัญหาขนาดใหญ่
from qiskit.quantum_info import SparsePauliOp
import numpy as np
hamiltonian = SparsePauliOp.from_list(
[("YZ", 0.3980), ("ZI", -0.3980), ("ZZ", -0.0113), ("XX", 0.1810)]
)
A = np.array(hamiltonian)
eigenvalues, eigenvectors = np.linalg.eigh(A)
print("The ground state energy is ", min(eigenvalues))
The ground state energy is -0.702930394459531
มีตัวเลือก ansatz สำเร็จรูปหลายตัวใน Qiskit เราจะใช้ efficient_su2
# Pre-defined ansatz circuit and operator class for Hamiltonian
from qiskit.circuit.library import efficient_su2
# Note that it is more common to place initial 'h' gates outside the ansatz.
# Here we specifically wanted this layer structure.
ansatz = efficient_su2(
hamiltonian.num_qubits, su2_gates=["h", "rz", "y"], entanglement="circular", reps=1
)
num_params = ansatz.num_parameters
print("This circuit has ", num_params, "parameters")
ansatz.decompose().draw("mpl", style="iqp")
This circuit has 4 parameters
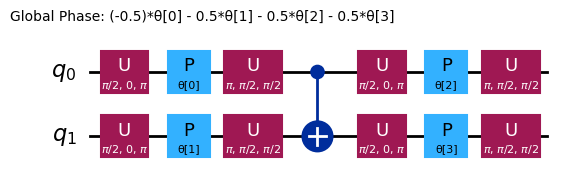
ansatz ที่แตกต่างกันจะมีโครงสร้าง entangling และ rotation gate ต่างกัน ตัวที่แสดงที่นี่ใช้ CNOT gate สำหรับการ entangle และทั้ง Y gate และ parametrized RZ gate สำหรับ rotation สังเกตขนาดของ parameter space นี้ หมายความว่าเราต้อง minimize cost function บนตัวแปร 4 ตัว (พารามิเตอร์สำหรับ RZ gate) ซึ่งสามารถขยายขนาดได้ แต่ไม่ได้ไม่มีขีดจำกัด การรันปัญหาที่คล้ายกันบน qubit 4 ตัว โดยใช้ reps เริ่มต้น 3 ตัวสำหรับ efficient_su2 จะให้ variational parameter 16 ตัว
3.2 ขั้นตอนที่ 2: เพิ่มประสิทธิภาพสำหรับฮาร์ดแวร์เป้าหมาย
ansatz ถูกเขียนโดยใช้ gate ที่คุ้นเคย แต่ circuit ของเราต้อง transpile เพื่อใช้ basis gate ที่สามารถนำไปใช้บนควอนตัมคอมพิวเตอร์แต่ละเครื่อง เราเลือก backend ที่ว่างงานน้อยที่สุด
# runtime imports
from qiskit_ibm_runtime import QiskitRuntimeService, Session
from qiskit_ibm_runtime import EstimatorV2 as Estimator
# To run on hardware, select the backend with the fewest number of jobs in the queue
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
print(backend)
<IBMBackend('ibm_torino')>
ตอนนี้เราสามารถ transpile circuit สำหรับฮาร์ดแวร์นี้และแสดงภาพ transpiled ansatz ของเรา
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
target = backend.target
pm = generate_preset_pass_manager(target=target, optimization_level=3)
ansatz_isa = pm.run(ansatz)
ansatz_isa.draw(output="mpl", idle_wires=False, style="iqp")

หมายเหตุว่า gate ที่ใช้เปลี่ยนไป และ qubit ใน circuit นามธรรมของเราถูกแมปไปยัง qubit ที่มีหมายเลขต่างกันบนควอนตัมคอมพิวเตอร์ เราต้องแมป Hamiltonian ของเราให้เหมือนกันเพื่อให้ผลลัพธ์มีความหมาย
hamiltonian_isa = hamiltonian.apply_layout(layout=ansatz_isa.layout)
3.3 ขั้นตอนที่ 3: รันบนฮาร์ดแวร์เป้าหมาย
3.3.1 รายงานค่าที่ได้
เรานิยาม cost function ที่นี่ซึ่งรับ argument ที่เป็นโครงสร้างที่เราสร้างในขั้นตอนก่อนหน้า: พารามิเตอร์, ansatz และ Hamiltonian นอกจากนี้ยังใช้ Estimator ที่เรายังไม่ได้นิยาม เรารวมโค้ดเพื่อติดตาม history ของ cost function เพื่อให้เราสามารถตรวจสอบพฤติกรรม convergence ได้
def cost_func(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from Estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (EstimatorV2): Estimator primitive instance
cost_history_dict: Dictionary for storing intermediate results
Returns:
float: Energy estimate
"""
pub = (ansatz, [hamiltonian], [params])
result = estimator.run(pubs=[pub]).result()
energy = result[0].data.evs[0]
cost_history_dict["iters"] += 1
cost_history_dict["prev_vector"] = params
cost_history_dict["cost_history"].append(energy)
print(f"Iters. done: {cost_history_dict['iters']} [Current cost: {energy}]")
return energy
cost_history_dict = {
"prev_vector": None,
"iters": 0,
"cost_history": [],
}
เป็นประโยชน์อย่างมากถ้าคุณสามารถเลือกค่าพารามิเตอร์เริ่มต้นตามความรู้เกี่ยวกับปัญหาและลักษณะของ target state เราจะไม่สมมติความรู้ดังกล่าวและใช้ค่าสุ่มเริ่มต้น
x0 = 2 * np.pi * np.random.random(num_params)
# This required 13 min, 20 s QPU time on an Eagle processor, 28 min total time.
with Session(backend=backend) as session:
estimator = Estimator(mode=session)
estimator.options.default_shots = 10000
res = minimize(
cost_func,
x0,
args=(ansatz_isa, hamiltonian_isa, estimator),
method="cobyla",
options={"maxiter": 50},
)
Iters. done: 1 [Current cost: 0.010575798722044727]
Iters. done: 2 [Current cost: 0.004040015974440895]
Iters. done: 3 [Current cost: 0.0020213258785942503]
Iters. done: 4 [Current cost: 0.18723082446726014]
Iters. done: 5 [Current cost: -0.2746792152068885]
Iters. done: 6 [Current cost: -0.3094547651648519]
Iters. done: 7 [Current cost: -0.05281985428356641]
Iters. done: 8 [Current cost: 0.00808560303514377]
Iters. done: 9 [Current cost: -0.0014821685303514388]
Iters. done: 10 [Current cost: -0.004759824281150161]
Iters. done: 11 [Current cost: 0.09942328705995292]
Iters. done: 12 [Current cost: 0.01092366214057508]
Iters. done: 13 [Current cost: 0.05017497496069776]
Iters. done: 14 [Current cost: 0.13028868414310696]
Iters. done: 15 [Current cost: 0.013747803514376994]
Iters. done: 16 [Current cost: 0.2583072432944498]
Iters. done: 17 [Current cost: -0.14422125655131562]
Iters. done: 18 [Current cost: -0.0004950150347678081]
Iters. done: 19 [Current cost: 0.00681082268370607]
Iters. done: 20 [Current cost: -0.0023377795527156544]
Iters. done: 21 [Current cost: 0.6027665591169237]
Iters. done: 22 [Current cost: 0.00596641373801917]
Iters. done: 23 [Current cost: -0.008318769968051117]
Iters. done: 24 [Current cost: -0.00026683306709265246]
Iters. done: 25 [Current cost: -0.007648222843450479]
Iters. done: 26 [Current cost: 0.004121086261980831]
Iters. done: 27 [Current cost: -0.004075019968051117]
Iters. done: 28 [Current cost: -0.004419369009584665]
Iters. done: 29 [Current cost: 0.213185460054037]
Iters. done: 30 [Current cost: -0.06505919572162797]
Iters. done: 31 [Current cost: -0.5334241316590271]
Iters. done: 32 [Current cost: 0.00218370607028754]
Iters. done: 33 [Current cost: 0.09579352143666908]
Iters. done: 34 [Current cost: -0.009274800319488819]
Iters. done: 35 [Current cost: -0.44395141360688106]
Iters. done: 36 [Current cost: 0.011747104632587858]
Iters. done: 37 [Current cost: -0.003344149361022364]
Iters. done: 38 [Current cost: 0.19138183916486304]
Iters. done: 39 [Current cost: 0.013513931813145209]
เราสามารถดู raw output
res
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -0.5334241316590271
x: [ 1.024e+00 6.459e+00 3.625e+00 4.007e+00]
nfev: 39
maxcv: 0.0
3.4 ขั้นตอนที่ 4: Post-process ผลลัพธ์
ถ้ากระบวนการสิ้นสุดอย่างถูกต้อง ค่าใน dictionary ของเราควรเท่ากับ solution vector และจำนวน function evaluation ทั้งหมดตามลำดับ ซึ่งง่ายต่อการตรวจสอบ:
cost_history_dict
{'prev_vector': array([1.02397956, 6.45886604, 3.62479262, 4.00744128]),
'iters': 39,
'cost_history': [np.float64(0.010575798722044727),
np.float64(0.004040015974440895),
np.float64(0.0020213258785942503),
np.float64(0.18723082446726014),
np.float64(-0.2746792152068885),
np.float64(-0.3094547651648519),
np.float64(-0.05281985428356641),
np.float64(0.00808560303514377),
np.float64(-0.0014821685303514388),
np.float64(-0.004759824281150161),
np.float64(0.09942328705995292),
np.float64(0.01092366214057508),
np.float64(0.05017497496069776),
np.float64(0.13028868414310696),
np.float64(0.013747803514376994),
np.float64(0.2583072432944498),
np.float64(-0.14422125655131562),
np.float64(-0.0004950150347678081),
np.float64(0.00681082268370607),
np.float64(-0.0023377795527156544),
np.float64(0.6027665591169237),
np.float64(0.00596641373801917),
np.float64(-0.008318769968051117),
np.float64(-0.00026683306709265246),
np.float64(-0.007648222843450479),
np.float64(0.004121086261980831),
np.float64(-0.004075019968051117),
np.float64(-0.004419369009584665),
np.float64(0.213185460054037),
np.float64(-0.06505919572162797),
np.float64(-0.5334241316590271),
np.float64(0.00218370607028754),
np.float64(0.09579352143666908),
np.float64(-0.009274800319488819),
np.float64(-0.44395141360688106),
np.float64(0.011747104632587858),
np.float64(-0.003344149361022364),
np.float64(0.19138183916486304),
np.float64(0.013513931813145209)]}
fig, ax = plt.subplots()
x = np.linspace(0, 10, 50)
# Define the constant function
constant = -0.7029
y_constant = np.full_like(x, constant)
ax.plot(
range(cost_history_dict["iters"]), cost_history_dict["cost_history"], label="VQE"
)
ax.set_xlabel("Iterations")
ax.set_ylabel("Cost")
ax.plot(y_constant, label="Target")
plt.legend()
plt.draw()

IBM Quantum มีข้อเสนอ upskilling อื่นๆ ที่เกี่ยวข้องกับ VQE ถ้าพร้อมนำ VQE ไปใช้งานจริง ดู tutorial: Ground-state energy estimation of the Heisenberg chain with VQE หากต้องการข้อมูลเพิ่มเติมเกี่ยวกับการสร้าง molecular Hamiltonian ดู บทเรียนนี้ ใน course Quantum chemistry with VQE ของเรา ถ้าสนใจทำความเข้าใจเชิงลึกเกี่ยวกับวิธี variational algorithm เช่น VQE ทำงานอย่างไร แนะนำ course Variational Algorithm Design
ทดสอบความเข้าใจ
ในส่วนนี้ เราคำนวณ ground state energy จาก Hamiltonian ถ้าเราต้องการนำสิ่งนี้ไปใช้กับการกำหนดรูปทรงของโมเลกุล เราจะขยายสิ่งนี้อย่างไร?
Answer
เราต้องแนะนำตัวแปรสำหรับระยะห่างระหว่างอะตอม และมุมระหว่างพันธะ เราต้องเปลี่ยนแปลงสิ่งเหล่านี้ สำหรับการเปลี่ยนแปลงแต่ละครั้ง เราจะสร้าง Hamiltonian ใหม่ (เนื่องจาก operator ที่อธิบายพลังงานขึ้นอยู่กับรูปทรงอย่างแน่นอน) สำหรับ Hamiltonian แต่ละตัวที่สร้างขึ้นและแมปลงบน qubit เราต้องทำการ optimization เช่นเดียวกับที่ทำข้างต้น จากปัญหา optimization ที่ converge แล้วทั้งหมดนั้น รูปทรงที่ให้พลังงานต่ำสุดจะเป็นรูปทรงที่ธรรมชาติเลือก สิ่งนี้ซับซ้อนกว่าที่แสดงข้างต้นมาก การคำนวณดังกล่าวทำสำหรับโมเลกุลที่ง่ายที่สุดคือ ที่นี่
4. ความสัมพันธ์ของ VQE กับวิธีอื่นๆ
ในส่วนนี้ เราจะทบทวนข้อดีและข้อเสียของแนวทาง VQE ดั้งเดิมและชี้ให้เห็นความสัมพันธ์กับอัลกอริทึมใหม่ๆ ที่ล้ำหน้ากว่า
4.1 จุดแข็งและจุดอ่อนของ VQE
จุดแข็งบางส่วนได้ถูกชี้ให้เห็นแล้ว ได้แก่:
- ความเหมาะสมกับฮาร์ดแวร์ปัจจุบัน: อัลกอริทึมควอนตัมบางตัวต้องการอัตราข้อผิดพลาดที่ต่ำกว่ามาก ใกล้เคียงกับ large scale fault tolerance VQE ไม่ต้องการ สามารถนำไปใช้บนควอนตัมคอมพิวเตอร์ปัจจุบันได้
- Circuit ที่ตื้น: VQE มักใช้ quantum circuit ที่ค่อนข้างตื้น ทำให้ VQE มีความอ่อนไหวต่อ gate error สะสมน้อยลงและเหมาะสำหรับเทคนิค error mitigation หลายอย่าง แน่นอนว่า circuit ไม่ตื้นเสมอไป ขึ้นอยู่กับ ansatz ที่ใช้
- ความหลากหลาย: VQE สามารถ (ในหลักการ) นำไปใช้กับปัญหาใดๆ ที่สามารถเขียนเป็นปัญหา eigenvalue/eigenvector มีข้อแม้หลายอย่างที่ทำให้ VQE ไม่ปฏิบัติจริงหรือเสียเปรียบสำหรับปัญหาบางอย่าง บางส่วนสรุปด้านล่าง
จุดอ่อนบางส่วนของ VQE และปัญหาที่ไม่สามารถนำไปใช้ได้จริงได้อธิบายข้างต้นด้วย ได้แก่:
- ลักษณะ Heuristic: VQE ไม่รับประกัน convergence ไปยัง ground state energy ที่ถูกต้อง เนื่องจากประสิทธิภาพขึ้นอยู่กับการเลือก ansatz และวิธี optimization [1-2] ถ้าเลือก ansatz ที่แย่ซึ่งขาด entanglement ที่จำเป็นสำหรับ ground state ที่ต้องการ ไม่มี classical optimizer ใดสามารถเข้าถึง ground state นั้นได้
- พารามิเตอร์อาจมีจำนวนมาก: ansatz ที่มี expressivity สูงอาจมีพารามิเตอร์มากจนการทำ minimization iteration ใช้เวลานานมาก
- ต้นทุนการวัดสูง: ใน VQE Estimator ถูกใช้เพื่อประมาณค่าความคาดหวังของแต่ละ term ใน Hamiltonian Hamiltonian ที่สนใจส่วนใหญ่จะมี term ที่ไม่สามารถประมาณพร้อมกันได้ ซึ่งอาจทำให้ VQE ใช้ทรัพยากรมากสำหรับระบบขนาดใหญ่ที่มี Hamiltonian ที่ซับซ้อน [1]
- ผลของ noise: เมื่อ classical optimizer กำลังค้นหา minimum การคำนวณที่มี noise อาจทำให้มันสับสนและพาไปผิดทางจาก minimum ที่แท้จริงหรือชะลอ convergence วิธีแก้ปัญหาที่เป็นไปได้คือการใช้เทคนิค error mitigation และ error suppression ขั้นสูง [2-3] จาก IBM
- Barren plateau: พื้นที่ที่ gradient หายไป [2-3] มีอยู่แม้ในกรณีที่ไม่มี noise แต่ noise ทำให้รุนแรงขึ้นเนื่องจากการเปลี่ยนแปลงของค่าความคาดหวังเนื่องจาก noise อาจใหญ่กว่าการเปลี่ยนแปลงจากการอัปเดตพารามิเตอร์ในพื้นที่ barren เหล่านี้
4.2 ความสัมพันธ์กับแนวทางอื่นๆ
Adapt-VQE
อัลกอริทึม ADAPT-VQE (Adaptive Derivative-Assembled Pseudo-Trotter Variational Quantum Eigensolver) เป็นการปรับปรุงของอัลกอริทึม VQE ดั้งเดิม ออกแบบมาเพื่อปรับปรุงประสิทธิภาพ ความแม่นยำ และความสามารถในการขยายขนาดสำหรับการจำลองควอนตัม โดยเฉพาะใน quantum chemistry
อัลกอริทึม VQE ดั้งเดิมที่อธิบายตลอดบทเรียนนี้ใช้ ansatz ที่กำหนดไว้ล่วงหน้าและคงที่เพื่อประมาณ ground state ของระบบ ในกรณีของเรา เราใช้ efficient_su2 ที่มี repetition เดี่ยว โดยใช้ Y และ RZ rotation gate แม้ว่าพารามิเตอร์ใน RZ gate จะเปลี่ยนแปลง แต่โครงสร้างของ ansatz นี้และ gate ที่ใช้ไม่เปลี่ยนแปลง
ADAPT-VQE แก้ไขข้อจำกัดของ VQE ผ่านการสร้าง ansatz แบบ adaptive แทนที่จะเริ่มต้นด้วย ansatz ที่คงที่ ADAPT-VQE สร้าง ansatz แบบ dynamically ทีละขั้น ในแต่ละขั้น มันเลือก operator จาก predefined pool (เช่น fermionic excitation operator) ที่มี gradient ใหญ่ที่สุดเทียบกับพลังงาน ซึ่งรับประกันว่าเพิ่มเฉพาะ operator ที่มีผลกระทบมากที่สุดเท่านั้น ส่งผลให้ได้ ansatz ที่กะทัดรัดและมีประสิทธิภาพ [4-6] แนวทางนี้อาจให้ประโยชน์หลายอย่าง:
- Circuit Depth ลดลง: โดยการขยาย ansatz แบบ incremental และเน้นเฉพาะ operator ที่จำเป็น ADAPT-VQE ลด gate operation เมื่อเทียบกับแนวทาง VQE แบบดั้งเดิม [5,7]
- ความแม่นยำปรับปรุง: ลักษณะ adaptive ทำให้ ADAPT-VQE กู้คืน correlation energy ได้มากขึ้นในแต่ละขั้น ทำให้มีประสิทธิภาพเป็นพิเศษสำหรับระบบที่มีความสัมพันธ์สูงซึ่ง VQE แบบดั้งเดิมทำได้ยาก [8,9]
- Scalability และความทนทานต่อ Noise: ansatz ที่กะทัดรัดลดการสะสมของ gate error ลดค่าใช้จ่ายในการคำนวณ และจำกัดจำนวน variational parameter ที่ต้อง minimize
ADAPT-VQE ยังไม่สมบูรณ์แบบ ในบางกรณีอาจติดหรือช้าลงเนื่องจาก local minimum และอาจประสบกับ over-parameterization นอกจากนี้ยังอาจใช้ทรัพยากรค่อนข้างมาก เนื่องจากต้องการการคำนวณ gradient และการเพิ่มประสิทธิภาพพารามิเตอร์ด้วยโครงสร้าง gate หลายแบบ
Quantum phase estimation (QPE)
QPE มีวัตถุประสงค์คล้ายกับ VQE แต่การนำไปใช้งานต่างกันมาก QPE ต้องการควอนตัมคอมพิวเตอร์แบบ fault-tolerant เนื่องจาก quantum circuit ที่มีความลึกโดยทั่วไปและระดับ coherence สูงที่ต้องการ เมื่อ QPE สามารถนำไปใช้งานได้ มันจะแม่นยำกว่า VQE วิธีหนึ่งในการอธิบายความแตกต่างคือผ่านความแม่นยำเป็นฟังก์ชันของ circuit depth QPE บรรลุความแม่นยำ ด้วย circuit depth ที่ scale เป็น [10] VQE ต้องการตัวอย่าง เพื่อบรรลุความแม่นยำเดียวกัน [10,11]
Krylov, SQD, QSCI และอื่นๆ ใน course นี้
VQE ช่วยสร้าง quantum algorithm ที่ยังคงพึ่งพาคอมพิวเตอร์คลาสสิก ไม่เพียงแต่สำหรับการใช้งานควอนตัมคอมพิวเตอร์เท่านั้น แต่ยังสำหรับส่วนสำคัญของอัลกอริทึมด้วย อัลกอริทึมดังกล่าวหลายตัวเป็นจุดสนใจของ course ที่เหลือ ที่นี่ เราให้คำอธิบายเบื้องต้นของบางส่วน เพียงเพื่อเปรียบเทียบกับ VQE จะอธิบายอย่างละเอียดมากขึ้นในบทเรียนถัดไป
Krylov quantum diagonalization (KQD)
Krylov subspace method เป็นวิธีฉาย matrix ลงบน subspace เพื่อลดมิติและทำให้จัดการได้ง่ายขึ้น ในขณะที่รักษาคุณสมบัติสำคัญไว้ เคล็ดลับหนึ่งในวิธีนี้คือการสร้าง subspace ที่รักษาคุณสมบัติเหล่านี้ ปรากฎว่าการสร้าง subspace นี้มีความเกี่ยวข้องอย่างใกล้ชิดกับวิธีที่ได้รับการยอมรับบนควอนตัมคอมพิวเตอร์ที่เรียกว่า Trotterization
มีเวอร์ชันต่างๆ ของ quantum Krylov method แต่โดยทั่วไปแนวทางคือ:
- ใช้ควอนตัมคอมพิวเตอร์เพื่อสร้าง subspace (Krylov subspace) ผ่าน Trotterization
- ฉาย matrix ที่สนใจลงบน Krylov subspace นั้น
- Diagonalize Hamiltonian ที่ฉายใหม่โดยใช้คอมพิวเตอร์คลาสสิก
Sampling-based quantum diagonalization (SQD)
Sampling-based quantum diagonalization (SQD) มีความเกี่ยวข้องกับ Krylov method ตรงที่มันก็พยายามลดมิติของ matrix ที่จะ diagonalize ในขณะที่รักษาคุณสมบัติสำคัญด้วย SQD ทำสิ่งนี้ในลักษณะต่อไปนี้:
- เริ่มต้นด้วยการเดาเริ่มต้นสำหรับ ground state และเตรียมระบบในสถานะ ground state นั้น
- ใช้ Sampler สุ่มตัวอย่าง bitstring ที่ประกอบเป็นสถานะนี้
- ใช้ชุดของ computational basis state จาก Sampler เป็น subspace สำหรับฉาย matrix ที่สนใจ
- Diagonalize matrix ที่เล็กลงที่ฉายแล้วโดยใช้คอมพิวเตอร์คลาสสิก
สิ่งนี้มีความเกี่ยวข้องกับ VQE ตรงที่ใช้การคำนวณทั้งคลาสสิกและควอนตัมสำหรับองค์ประกอบอัลกอริทึมสำคัญ ทั้งคู่ยังแบ่งปันความต้องการว่าเราต้องเตรียม good initial guess หรือ ansatz แต่การกระจายงานระหว่างคอมพิวเตอร์คลาสสิกและควอนตัมใน SQD คล้ายกับ Krylov method มากกว่า
ในความเป็นจริง Krylov method และ SQD ได้ถูกรวมกันเป็น sampling-based Krylov quantum diagonalization (SKQD) [12] ไปแล้วเมื่อไม่นานมานี้
Quantum subspace configuration interaction
Quantum Selected Configuration Interaction (QSCI) [13] เป็นอัลกอริทึมที่สร้าง ground state โดยประมาณของ Hamiltonian โดยการสุ่มตัวอย่าง trial wave function เพื่อระบุ computational basis state ที่สำคัญในการสร้าง subspace สำหรับ classical diagonalization ทั้ง SQD และ QSCI ใช้ควอนตัมคอมพิวเตอร์เพื่อสร้าง reduced subspace จุดแข็งเพิ่มเติมของ QSCI อยู่ที่การเตรียมสถานะ โดยเฉพาะในบริบทของปัญหาเคมี มันใช้กลยุทธ์ต่างๆ เช่น การใช้ time-evolved state [14] และชุดของ chemistry-inspired ansatz โดยการเน้นที่การเตรียมสถานะอย่างมีประสิทธิภาพ QSCI ลดค่าใช้จ่ายการคำนวณควอนตัมสำหรับ chemical Hamiltonian ในขณะที่รักษา fidelity สูงและใช้ประโยชน์จาก noise robustness จากเทคนิค quantum state sampling [15] QSCI ยังให้เทคนิคการสร้างแบบ adaptive ที่ให้ ansatz มากขึ้นเพื่อผลลัพธ์ที่ดีขึ้น
workflow เริ่มต้นของ QSCI สำหรับปัญหาเคมีคือ:
- สร้าง molecular Hamiltonian โดยใช้ software ที่ต้องการ (เช่น SciPy)
- เตรียมอัลกอริทึม QSCI โดยเลือก initial state ที่เหมาะสมและ chemistry-inspired ansatz พร้อมชุดพารามิเตอร์ที่เลือกไว้ล่วงหน้า
- สุ่มตัวอย่าง basis state สำคัญและ diagonalize Hamiltonian โดยใช้คอมพิวเตอร์คลาสสิกเพื่อหา ground state energy
- มักใช้ configuration recovery [16] และ symmetry postselection [15] เป็นเทคนิค post processing
- ตัวเลือก workflow ของ adaptive QSCI มี optimization loop เพิ่มเติมจากขั้นตอน 2 ถึง 3 โดยใช้ ansatz มากขึ้นพร้อม random initial state
ทดสอบความเข้าใจ
VQE มีอะไรเหมือนกับวิธีอื่นๆ ทั้งหมดที่ระบุข้างต้น (ยกเว้น QPE ที่ไม่ได้อธิบายอย่างละเอียด)
Answer
ทุกวิธีมี trial state หรือ wave function บางอย่าง ทุกวิธีทำงานได้ดีที่สุดเมื่อการเดาเริ่มต้นสำหรับ trial state นี้ดีเยี่ยม
คำตอบที่ถูกต้องอีกอย่างคือ ทุกวิธีนำไปใช้งานได้ง่ายที่สุดเมื่อ Hamiltonian วัดได้ง่าย (สามารถจัดกลุ่มเป็นกลุ่มของ Pauli operator ที่ commute กันได้ค่อนข้างน้อยกลุ่ม)
VQE ไม่มีอะไรเหมือนกับวิธีอื่นๆ ที่ระบุข้างต้นเลยในด้านไหน?
Answer
Classical optimizer ไม่มีวิธีอื่นใดที่ใช้ classical optimization algorithm เพื่อเลือก variational parameter
References
[2] https://en.wikipedia.org/wiki/Variational_quantum_eigensolver
[3] https://journals.aps.org/prapplied/abstract/10.1103/PhysRevApplied.19.024047
[4] https://arxiv.org/abs/2111.05176
[6] https://inquanto.quantinuum.com/tutorials/InQ_tut_fe4n2_2.html
[7] https://www.nature.com/articles/s41467-019-10988-2
[8] https://arxiv.org/abs/2210.15438
[9] https://journals.aps.org/prresearch/abstract/10.1103/PhysRevResearch.6.013254
[10] https://arxiv.org/html/2403.09624v1
[11] https://www.nature.com/articles/s42005-023-01312-y
[13] https://arxiv.org/abs/1802.00171
[14] https://arxiv.org/abs/2103.08505
[15] https://arxiv.org/html/2501.09702v1
[16] https://quri-sdk.qunasys.com/docs/examples/quri-algo-vm/qsci/