การเข้ารหัสข้อมูล
บทนำและสัญลักษณ์
เพื่อใช้อัลกอริทึมเชิงควอนตัม ข้อมูลแบบดั้งเดิม (classical) จะต้องถูกนำเข้าสู่ Circuit ควอนตัมในรูปแบบใดรูปแบบหนึ่ง กระบวนการนี้มักเรียกว่า การเข้ารหัส (encoding) ข้อมูล หรือบางครั้งก็เรียกว่า data loading ลองนึกถึงแนวคิดของ feature mapping จากบทเรียนก่อนหน้า ซึ่งหมายถึงการแมปคุณสมบัติของข้อมูลจากปริภูมิหนึ่งไปยังอีกปริภูมิหนึ่ง การถ่ายโอนข้อมูลแบบดั้งเดิมไปยังคอมพิวเตอร์ควอนตัมก็เป็นการแมปในแบบหนึ่ง และอาจเรียกได้ว่าเป็น feature mapping ในทางปฏิบัติ feature mapping ที่มีอยู่แล้วใน Qiskit (เช่น z_feature_map และ zz_feature_map) มักจะมีทั้ง rotation layer และ entangling layer ที่ขยายสถานะไปสู่มิติจำนวนมากในปริภูมิ Hilbert กระบวนการเข้ารหัสนี้เป็นส่วนสำคัญของอัลกอริทึมการเรียนรู้ด้วยเครื่องเชิงควอนตัม และส่งผลโดยตรงต่อความสามารถในการคำนวณของอัลกอริทึมนั้น
เทคนิคการเข้ารหัสบางอย่างด้านล่างสามารถจำลองด้วย classical ได้อย่างมีประสิทธิภาพ ซึ่งเห็นได้ชัดโดยเฉพาะในวิธีที่ให้ผลลัพธ์เป็น product state (กล่าวคือไม่มีการ entangle Qubit) และจำไว้ว่า quantum utility มีแนวโน้มจะเกิดขึ้นในบริเวณที่ความซับซ้อนเชิงควอนตัมของชุดข้อมูลสอดคล้องกับวิธีการเข้ารหัสเป็นอย่างดี ดังนั้นมีความเป็นไปได้สูงที่คุณจะต้องเขียน Circuit การเข้ารหัสของตัวเอง ที่นี่เราแสดงกลยุทธ์การเข้ารหัสที่หลากหลายเพื่อให้คุณสามารถเปรียบเทียบแต่ละแบบและเห็นว่ามีอะไรเป็นไปได้บ้าง มีข้อความทั่วไปบางอย่างที่สามารถพูดได้เกี่ยวกับความเป็นประโยชน์ของเทคนิคการเข้ารหัส ตัวอย่างเช่น efficient_su2 (ดูด้านล่าง) ที่ใช้รูปแบบ entangling แบบเต็มมีแนวโน้มสูงมากที่จะจับคุณลักษณะเชิงควอนตัมของข้อมูลได้ดีกว่าวิธีที่ให้ผลเป็น product state (เช่น z_feature_map) แต่นั่นไม่ได้หมายความว่า efficient_su2 จะเพียงพอหรือเหมาะสมกับชุดข้อมูลของคุณมากพอที่จะทำให้เกิด quantum speed-up ซึ่งต้องอาศัยการพิจารณาโครงสร้างของข้อมูลที่กำลังสร้างแบบจำลองหรือจำแนกอย่างรอบคอบ นอกจากนี้ยังมีการแลกเปลี่ยนกับความลึกของ Circuit เนื่องจาก feature map หลายตัวที่ entangle Qubit ทั้งหมดใน Circuit ทำให้ Circuit มีความลึกมาก เกินกว่าจะได้ผลลัพธ์ที่ใช้ประโยชน์ได้บนคอมพิวเตอร์ควอนตัมในปัจจุบัน
สัญลักษณ์
ชุดข้อมูลคือเซตของเวกเตอร์ข้อมูล ตัว: โดยแต่ละเวกเตอร์มีมิติ นั่นคือ ซึ่งสามารถขยายไปสู่คุณสมบัติข้อมูลแบบ complex ได้ ในบทเรียนนี้เราอาจใช้สัญลักษณ์เหล่านี้สำหรับชุดข้อมูลทั้งหมด และองค์ประกอบเฉพาะ เช่น บ้างเป็นครั้งคราว แต่ส่วนใหญ่เราจะอ้างถึงการโหลดเวกเตอร์เพียงตัวเดียวจากชุดข้อมูลในแต่ละครั้ง และมักจะอ้างถึงเวกเตอร์ตัวเดียวที่มี คุณสมบัติว่า
นอกจากนี้ เป็นเรื่องปกติที่จะใช้สัญลักษณ์ เพื่ออ้างถึง feature mapping ของเวกเตอร์ข้อมูล ในการคำนวณเชิงควอนตัมโดยเฉพาะ มักใช้ ซึ่งเป็นสัญลักษณ์ที่เน้นลักษณะ unitary ของการดำเนินการเหล่านี้ สามารถใช้สัญลักษณ์เดียวกันสำหรับทั้งสองอย่างได้อย่างถูกต้อง เพราะทั้งคู่เป็น feature mapping ตลอดทั้งคอร์สนี้ เราใช้:
- เมื่อพูดถึง feature mapping ในการเรียนรู้ด้วยเครื่องโดยทั่วไป และ
- เมื่อพูดถึงการนำ feature mapping ไปใช้งานใน Circuit
การ normalize และการสูญเสียข้อมูล
ในการเรียนรู้ด้วยเครื่องแบบดั้งเดิม คุณสมบัติของข้อมูลฝึกสอนมักถูก "normalize" หรือปรับขนาด ซึ่งมักช่วยปรับปรุงประสิทธิภาพของโมเดล วิธีทั่วไปวิธีหนึ่งคือการใช้ min-max normalization หรือ standardization ใน min-max normalization คอลัมน์คุณสมบัติของเมทริกซ์ข้อมูล (สมมติว่าเป็นคุณสมบัติ ) จะถูก normalize ดังนี้:
โดย min และ max หมายถึงค่าต่ำสุดและสูงสุดของคุณสมบัติ จากเวกเตอร์ข้อมูล ตัวในชุดข้อมูล ค่าคุณสมบัติทั้งหมดจะอยู่ในช่วงหน่วย: สำหรับทุก ,
การ normalize เป็นแนวคิดพื้นฐานในกลศาสตร์ควอนตัมและการคำนวณเชิงควอนตัมด้วย แต่แตกต่างเล็กน้อยจาก min-max normalization การ normalize ในกลศาสตร์ควอนตัมกำหนดให้ความยาว (ในบริบทของการคำนวณเชิงควอนตัม คือ 2-norm) ของเวกเตอร์สถานะ เท่ากับหนึ่ง: เพื่อให้ความน่าจะเป็นจากการวัดรวมกันได้ 1 โดยสถานะถูก normalize ด้วยการหารด้วย 2-norm กล่าวคือปรับขนาดด้วย
ในการคำนวณเชิงควอนตัมและกลศาสตร์ควอนตัม นี่ไม่ใช่การ normalize ที่มนุษย์กำหนดให้กับข้อมูล แต่เป็นคุณสมบัติพื้นฐานของสถานะควอนตัม ขึ้นอยู่กับรูปแบบการเข้ารหัสที่ใช้ ข้อจำกัดนี้อาจส่งผลต่อการปรับขนาดข้อมูลของคุณ ตัวอย่างเช่น ใน amplitude encoding (ดูด้านล่าง) เวกเตอร์ข้อมูลจะถูก normalize ตามที่กลศาสตร์ควอนตัมกำหนด ซึ่งส่งผลต่อการปรับขนาดของข้อมูลที่เข้ารหัส ส่วนใน phase encoding แนะนำให้ปรับขนาดค่าคุณสมบัติเป็น เพื่อป้องกันการสูญเสียข้อมูลจากผลของ modulo- เมื่อเข้ารหัสไปยังมุมเฟสของ Qubit[1,2]
วิธีการเข้ารหัส
ในส่วนถัดไป เราจะอ้างอิงชุดข้อมูลตัวอย่างแบบดั้งเดิมขนาดเล็ก ซึ่งประกอบด้วยเวกเตอร์ข้อมูล ตัว แต่ละตัวมี คุณสมบัติ:
จากสัญลักษณ์ที่แนะนำข้างต้น เราอาจพูดได้ว่าคุณสมบัติที่ ของเวกเตอร์ข้อมูลตัวที่ ในเซต คือ เป็นต้น
การเข้ารหัสแบบ Basis
Basis encoding เข้ารหัส bit string แบบดั้งเดิมความยาว bit ไปยัง computational basis state ของระบบ -Qubit ตัวอย่างเช่น สามารถแทนเป็น 4-bit string ว่า และโดยระบบ 4-Qubit เป็นสถานะควอนตัม โดยทั่วไป สำหรับ bit string ความยาว : สถานะ -Qubit ที่สอดคล้องกันคือ โดยที่ สำหรับ ขอสังเกตว่านี่เป็นการเข้ารหัสสำหรับคุณสมบัติเดียว
Basis encoding ในการคำนวณเชิงควอนตัมแทน bit แบบดั้งเดิมแต่ละ bit เป็น Qubit แยกกัน โดยแมปการแทนเลขฐานสองของข้อมูลตรงไปยังสถานะควอนตัมใน computational basis เมื่อต้องการเข้ารหัสหลายคุณสมบัติ แต่ละคุณสมบัติจะถูกแปลงเป็นรูปแบบเลขฐานสองก่อน จากนั้นกำหนดให้กับกลุ่ม Qubit ที่แตกต่างกัน โดยแต่ละกลุ่มต่อหนึ่งคุณสมบัติ และแต่ละ Qubit สะท้อน bit ในการแทนเลขฐานสองของคุณสมบัตินั้น
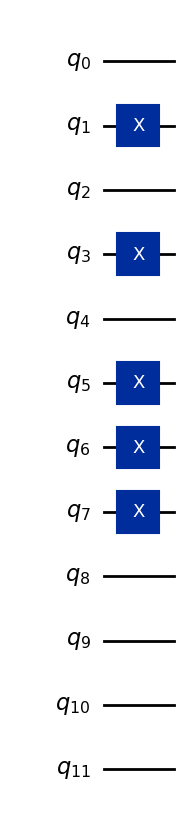
เพื่อเป็นตัวอย่าง ลองเข้ารหัสเวกเตอร์ (5, 7, 0)
สมมติว่าคุณสมบัติทั้งหมดถูกเก็บใน 4 bit (มากกว่าที่จำเป็น แต่เพียงพอสำหรับแทนจำนวนเต็มหลักเดียวในฐานสิบ):
5 → binary 0101
7 → binary 0111
0 → binary 0000
bit string เหล่านี้ถูกกำหนดให้กับ Qubit สามชุดละสี่ตัว ดังนั้น basis state ของ 12-Qubit โดยรวมคือ:
ที่นี่ Qubit สี่ตัวแรกแทนคุณสมบัติแรก Qubit สี่ตัวถัดไปแทนคุณสมบัติที่สอง และ Qubit สี่ตัวสุดท้ายแทนคุณสมบัติที่สาม โค้ดด้านล่างแปลงเวกเตอร์ข้อมูล (5,7,0) เป็นสถานะควอนตัม และสามารถนำไปใช้กับคุณสมบัติหลักเดียวอื่นได้
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit
from qiskit import QuantumCircuit
# Data point to encode
x = 5 # binary: 0101
y = 7 # binary: 0111
z = 0 # binary: 0000
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, "04b")] # [0,1,0,1]
y_bits = [int(b) for b in format(y, "04b")] # [0,1,1,1]
z_bits = [int(b) for b in format(z, "04b")] # [0,0,0,0]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,1,0,1,1,1,0,0,0,0]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw("mpl")
ทดสอบความเข้าใจ
อ่านคำถามด้านล่าง คิดคำตอบ แล้วคลิกสามเหลี่ยมเพื่อดูเฉลย
เขียนโค้ดเพื่อเข้ารหัสเวกเตอร์แรกในชุดข้อมูลตัวอย่าง :
โดยใช้ basis encoding
คำตอบ:
import math
from qiskit import QuantumCircuit
# Data point to encode
x = 4 # binary: 0100
y = 8 # binary: 1000
z = 5 # binary: 0101
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, '04b')] # [0,1,0,0]
y_bits = [int(b) for b in format(y, '04b')] # [1,0,0,0]
z_bits = [int(b) for b in format(z, '04b')] # [0,1,0,1]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,0,1,0,0,0,0,1,0,1]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw('mpl')
การเข้ารหัสแบบ Amplitude
Amplitude encoding เข้ารหัสข้อมูลไปยัง amplitude ของสถานะควอนตัม โดยแทนเวกเตอร์ข้อมูลแบบดั้งเดิมมิติ ที่ผ่านการ normalize แล้ว เป็น amplitude ของสถานะ -Qubit :
โดย คือมิติของเวกเตอร์ข้อมูลเช่นเดิม คือองค์ประกอบที่ ของ และ คือ computational basis state ที่ ที่นี่ คือค่าคงที่ normalization ที่ต้องหาจากข้อมูลที่เข้ารหัส นี่คือเงื่อนไข normalization ที่กำหนดโดยกลศาสตร์ควอนตัม:
โดยทั่วไป เงื่อนไขนี้แตกต่างจาก min/max normalization ที่ใช้สำหรับแต่ละคุณสมบัติในเวกเตอร์ข้อมูลทั้งหมด วิธีจัดการกับเรื่องนี้จะขึ้นอยู่กับปัญหาของคุณ แต่ไม่สามารถหลีกเลี่ยงเงื่อนไข normalization ของกลศาสตร์ควอนตัมข้างต้นได้
ใน amplitude encoding คุณสมบัติแต่ละอย่างในเวกเตอร์ข้อมูลจะถูกเก็บเป็น amplitude ของสถานะควอนตัมที่แตกต่างกัน เนื่องจากระบบ Qubit มี amplitude อยู่ ตัว การ amplitude encoding ของ คุณสมบัติจึงต้องการ Qubit
เพื่อเป็นตัวอย่าง ลองเข้ารหัสเวกเตอร์แรกในชุดข้อมูลตัวอย่าง นั่นคือ ด้วย amplitude encoding หลัง normalize เวกเตอร์ที่ได้จะเป็น:
และสถานะควอนตัม 2-Qubit ที่ได้จะเป็น:
ในตัวอย่างข้างต้น จำนวนคุณสมบัติในเวกเตอร์ ไม่ใช่เลขยกกำลังสอง เมื่อ ไม่ใช่เลขยกกำลังสอง เราเพียงแค่เลือกจำนวน Qubit ให้ และเติม amplitude vector ด้วยค่าที่ไม่มีความหมาย (ในที่นี้คือศูนย์)
เช่นเดียวกับ basis encoding เมื่อเราคำนวณสถานะที่จะเข้ารหัสชุดข้อมูลของเราแล้ว ใน Qiskit เราสามารถใช้ฟังก์ชัน initialize เพื่อเตรียมสถานะนั้น:
import math
desired_state = [
1 / math.sqrt(105) * 4,
1 / math.sqrt(105) * 8,
1 / math.sqrt(105) * 5,
1 / math.sqrt(105) * 0,
]
qc = QuantumCircuit(2)
qc.initialize(desired_state, [0, 1])
qc.decompose(reps=5).draw(output="mpl")

ข้อดีของ amplitude encoding คือต้องการเพียง Qubit ดังที่กล่าวไว้ข้างต้น อย่างไรก็ตาม อัลกอริทึมที่ตามมาต้องทำงานกับ amplitude ของสถานะควอนตัม และวิธีการเตรียมและวัดสถานะควอนตัมมักไม่มีประสิทธิภาพ
ทดสอบความเข้าใจ
อ่านคำถามด้านล่าง คิดคำตอบ แล้วคลิกสามเหลี่ยมเพื่อดูเฉลย
เขียนสถานะที่ผ่านการ normalize สำหรับการเข้ารหัสเวกเตอร์ต่อไปนี้ (ประกอบด้วยสองเวกเตอร์จากชุดข้อมูลตัวอย่าง):
โดยใช้ amplitude encoding
คำตอบ:
เพื่อเข้ารหัสตัวเลข 6 ตัว เราต้องมีอย่างน้อย 6 สถานะที่ใช้ amplitude ในการเข้ารหัส ซึ่งต้องการ 3 Qubit โดยใช้ค่าคงที่ normalization ที่ยังไม่ทราบค่า เราสามารถเขียนได้ว่า:
สังเกตว่า
ดังนั้น
สำหรับเวกเตอร์ข้อมูลเดิม เขียนโค้ดเพื่อสร้าง Circuit สำหรับโหลดคุณสมบัติข้อมูลเหล่านี้ด้วย amplitude encoding
คำตอบ:
desired_state = [
9 / math.sqrt(270),
8 / math.sqrt(270),
6 / math.sqrt(270),
2 / math.sqrt(270),
9 / math.sqrt(270),
2 / math.sqrt(270),
0,
0,
]
print(desired_state)
qc = QuantumCircuit(3)
qc.initialize(desired_state, [0, 1, 2])
qc.decompose(reps=8).draw(output="mpl")
[0.5477225575051662, 0.48686449556014766, 0.36514837167011077, 0.12171612389003691, 0.5477225575051662, 0.12171612389003691, 0, 0]

คุณอาจต้องจัดการกับเวกเตอร์ข้อมูลขนาดใหญ่มาก ลองพิจารณาเวกเตอร์
เขียนโค้ดเพื่อ normalize อัตโนมัติและสร้าง Circuit ควอนตัมสำหรับ amplitude encoding
คำตอบ:
มีคำตอบที่เป็นไปได้หลายแบบ นี่คือโค้ดที่แสดงขั้นตอนบางส่วนระหว่างทาง:
import numpy as np
from math import sqrt
init_list = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5]
qubits = round(np.log(len(init_list)) / np.log(2) + 0.4999999999)
need_length = 2**qubits
pad = need_length - len(init_list)
for i in range(0, pad):
init_list.append(0)
init_array = np.array(init_list) # Unnormalized data vector
length = sqrt(
sum(init_array[i] ** 2 for i in range(0, len(init_array)))
) # Vector length
norm_array = init_array / length # Normalized array
print("Normalized array:")
print(norm_array)
print()
qubit_numbers = []
for i in range(0, qubits):
qubit_numbers.append(i)
print(qubit_numbers)
qc = QuantumCircuit(qubits)
qc.initialize(norm_array, qubit_numbers)
qc.decompose(reps=7).draw(output="mpl")
Normalized array: [0.17342199 0.34684399 0.21677749 0.39019949 0.34684399 0.26013299 0.086711 0.39019949 0.086711 0.21677749 0.30348849 0. 0.1300665 0.30348849 0.21677749 0. ]
[0, 1, 2, 3]
คุณเห็นข้อดีของ amplitude encoding เมื่อเทียบกับ basis encoding ไหม ถ้ามี อธิบาย
คำตอบ:
อาจมีคำตอบหลายอย่าง คำตอบหนึ่งคือ เนื่องจากลำดับของ basis state มีการกำหนดไว้แล้ว การ amplitude encoding นี้จึงรักษาลำดับของตัวเลขที่เข้ารหัส และมักจะเข้ารหัสได้หนาแน่นกว่า
ข้อดีของ amplitude encoding คือต้องการเพียง Qubit สำหรับเวกเตอร์ข้อมูล -มิติ ( คุณสมบัติ) อย่างไรก็ตาม amplitude encoding โดยทั่วไปเป็นกระบวนการที่ไม่มีประสิทธิภาพ เนื่องจากต้องเตรียมสถานะแบบ arbitrary ซึ่งเป็น exponential ในจำนวน CNOT gate กล่าวอีกนัยหนึ่ง การเตรียมสถานะมีความซับซ้อนของรันไทม์แบบ polynomial ในจำนวนมิติ โดยที่ และ คือจำนวน Qubit Amplitude encoding "ให้การประหยัดเชิง exponential ในพื้นที่แลกกับการเพิ่มขึ้นเชิง exponential ในเวลา"[3] อย่างไรก็ตาม รันไทม์สามารถลดลงเหลือ ได้ในบางกรณี[4] สำหรับ quantum speedup แบบครบวงจร ต้องพิจารณาความซับซ้อนของรันไทม์การโหลดข้อมูลด้วย
Angle encoding
Angle encoding เป็นที่น่าสนใจในหลายโมเดล QML ที่ใช้ Pauli feature map เช่น quantum support vector machine (QSVM) และ variational quantum circuit (VQC) รวมถึงอื่นๆ Angle encoding มีความใกล้เคียงกับ phase encoding และ dense angle encoding ซึ่งนำเสนอด้านล่าง ที่นี่เราจะใช้คำว่า "angle encoding" เพื่ออ้างถึงการหมุนใน กล่าวคือการหมุนออกจากแกน ซึ่งทำได้เช่นโดย Gate หรือ Gate [1,3] จริงๆ แล้ว สามารถเข้ารหัสข้อมูลในการหมุนหรือการรวมกันของการหมุนใดก็ได้ แต่ เป็นที่นิยมในวรรณกรรม เราจึงเน้นที่มัน
เมื่อนำไปใช้กับ Qubit เดียว angle encoding จะให้การหมุนแกน Y ที่เป็นสัดส่วนกับค่าข้อมูล พิจารณาการเข้ารหัสคุณสมบัติเดียว (คุณสมบัติที่ ) จากเวกเตอร์ข้อมูลที่ ในชุดข้อมูล :
นอกจากนี้ angle encoding ยังสามารถทำได้ด้วย Gate แม้ว่าสถานะที่เข้ารหัสจะมี relative phase แบบ complex เมื่อเทียบกับ
Angle encoding แตกต่างจากสองวิธีก่อนหน้าที่กล่าวถึงในหลายด้าน ใน angle encoding:
- แต่ละค่าคุณสมบัติถูกแมปกับ Qubit ที่สอดคล้องกัน ทำให้ Qubit อยู่ใน product state
- เข้ารหัสค่าตัวเลขหนึ่งค่าในแต่ละครั้ง แทนที่จะเป็นคุณสมบัติทั้งหมดจากจุดข้อมูลหนึ่งพร้อมกัน
- ต้องการ Qubit สำหรับ คุณสมบัติข้อมูล โดยที่ โดยทั่วไปจะมีความเท่ากัน เราจะเห็นว่า เป็นไปได้อย่างไรในส่วนถัดไป
- Circuit ควอนตัมที่ได้มีความลึกคงที่ (โดยทั่วไปความลึกคือ 1 ก่อนการ Transpile)
Circuit ควอนตัมที่มีความลึกคงที่ทำให้เหมาะสมกับฮาร์ดแวร์ควอนตัมในปัจจุบันเป็นพิเศษ คุณสมบัติเพิ่มเติมอีกอย่างของการเข้ารหัสข้อมูลด้วย (และโดยเฉพาะการเลือกใช้ Y-axis angle encoding) คือมันสร้างสถานะควอนตัมที่มีค่า real ซึ่งมีประโยชน์สำหรับบางแอปพลิเคชัน สำหรับการหมุนแกน Y ข้อมูลถูกแมปด้วย Y-axis rotation gate โดยมุม real (Qiskit RYGate) เช่นเดียวกับ phase encoding (ดูด้านล่าง) เราแนะนำให้ปรับขนาดข้อมูลเพื่อให้ เพื่อป้องกันการสูญเสียข้อมูลและผลที่ไม่ต้องการอื่นๆ
โค้ด Qiskit ต่อไปนี้หมุน Qubit เดียวจากสถานะเริ่มต้น เพื่อเข้ารหัสค่าข้อมูล
from qiskit.quantum_info import Statevector
from math import pi
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
เราจะกำหนดฟังก์ชันเพื่อแสดงการกระทำต่อ state vector รายละเอียดของการนิยามฟังก์ชันไม่สำคัญ แต่ความสามารถในการแสดงภาพ state vector และการเปลี่ยนแปลงนั้นสำคัญ
import numpy as np
from qiskit.visualization.bloch import Bloch
from qiskit.visualization.state_visualization import _bloch_multivector_data
def plot_Nstates(states, axis, plot_trace_points=True):
"""This function plots N states to 1 Bloch sphere"""
bloch_vecs = [_bloch_multivector_data(s)[0] for s in states]
if axis is None:
bloch_plot = Bloch()
else:
bloch_plot = Bloch(axes=axis)
bloch_plot.add_vectors(bloch_vecs)
if len(states) > 1:
def rgba_map(x, num):
g = (0.95 - 0.05) / (num - 1)
i = 0.95 - g * num
y = g * x + i
return (0.0, y, 0.0, 0.7)
num = len(states)
bloch_plot.vector_color = [rgba_map(x, num) for x in range(1, num + 1)]
bloch_plot.vector_width = 3
bloch_plot.vector_style = "simple"
if plot_trace_points:
def trace_points(bloch_vec1, bloch_vec2):
# bloch_vec = (x,y,z)
n_points = 15
thetas = np.arccos([bloch_vec1[2], bloch_vec2[2]])
phis = np.arctan2(
[bloch_vec1[1], bloch_vec2[1]], [bloch_vec1[0], bloch_vec2[0]]
)
if phis[1] < 0:
phis[1] = phis[1] + 2 * pi
angles0 = np.linspace(phis[0], phis[1], n_points)
angles1 = np.linspace(thetas[0], thetas[1], n_points)
xp = np.cos(angles0) * np.sin(angles1)
yp = np.sin(angles0) * np.sin(angles1)
zp = np.cos(angles1)
pnts = [xp, yp, zp]
bloch_plot.add_points(pnts)
bloch_plot.point_color = "k"
bloch_plot.point_size = [4] * len(bloch_plot.points)
bloch_plot.point_marker = ["o"]
for i in range(len(bloch_vecs) - 1):
trace_points(bloch_vecs[i], bloch_vecs[i + 1])
bloch_plot.sphere_alpha = 0.05
bloch_plot.frame_alpha = 0.15
bloch_plot.figsize = [4, 4]
bloch_plot.render()
plot_Nstates(states, axis=None, plot_trace_points=True)

นั่นเป็นเพียงคุณสมบัติเดียวของเวกเตอร์ข้อมูลตัวเดียว เมื่อเข้ารหัส คุณสมบัติไปยังมุมหมุนของ Qubit สมมติสำหรับเวกเตอร์ข้อมูลที่ product state ที่เข้ารหัสจะมีลักษณะดังนี้:
เราสังเกตว่าสิ่งนี้เทียบเท่ากับ
ทดสอบความเข้าใจ
อ่านคำถามด้านล่าง คิดคำตอบ แล้วคลิกสามเหลี่ยมเพื่อดูเฉลย
เข้ารหัสเวกเตอร์ข้อมูล ด้วย angle encoding ตามที่อธิบายข้างต้น
คำตอบ:
qc = QuantumCircuit(3)
qc.ry(0, 0)
qc.ry(2 * math.pi / 4, 1)
qc.ry(2 * math.pi / 2, 2)
qc.draw(output="mpl")

โดยใช้ angle encoding ตามที่อธิบายข้างต้น ต้องใช้ Qubit กี่ตัวในการเข้ารหัส 5 คุณสมบัติ
คำตอบ: 5
Phase encoding
Phase encoding มีความคล้ายคลึงกับ angle encoding ที่อธิบายข้างต้นมาก มุมเฟสของ Qubit คือมุม real รอบแกน จาก +-axis ข้อมูลถูกแมปด้วยการหมุนเฟส โดยที่ (ดู Qiskit PhaseGate สำหรับข้อมูลเพิ่มเติม) แนะนำให้ปรับขนาดข้อมูลเพื่อให้ เพื่อป้องกันการสูญเสียข้อมูลและผลที่อาจไม่ต้องการอื่นๆ[1,2]
Qubit มักถูก initialize ในสถานะ ซึ่งเป็น eigenstate ของตัวดำเนินการหมุนเฟส หมายความว่าสถานะ Qubit ต้องถูกหมุนก่อนเพื่อนำ phase encoding ไปใช้ จึงสมเหตุสมผลที่จะ initialize สถานะด้วย Hadamard gate: Phase encoding บน Qubit เดียวหมายถึงการให้ relative phase ที่เป็นสัดส่วนกับค่าข้อมูล:
กระบวนการ phase encoding แมปแต่ละค่าคุณสมบัติกับเฟสของ Qubit ที่สอดคล้องกัน โดยรวมแล้ว phase encoding มีความลึกของ Circuit เท่ากับ 2 รวมทั้ง Hadamard layer ทำให้เป็นรูปแบบการเข้ารหัสที่มีประสิทธิภาพ สถานะ multi-qubit ที่เข้ารหัสแบบ phase ( Qubit สำหรับ คุณสมบัติ) เป็น product state:
โค้ด Qiskit ต่อไปนี้เตรียมสถานะเริ่มต้นของ Qubit เดียวโดยหมุนด้วย Hadamard gate ก่อน จากนั้นหมุนอีกครั้งด้วย phase gate เพื่อเข้ารหัสคุณสมบัติข้อมูล
qc = QuantumCircuit(1)
qc.h(0) # Hadamard gate rotates state down to Bloch equator
state1 = Statevector.from_instruction(qc)
qc.p(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
qc.draw("mpl", scale=1)

เราสามารถแสดงภาพการหมุนใน ด้วยฟังก์ชัน plot_Nstates ที่เรากำหนดไว้
plot_Nstates(states, axis=None, plot_trace_points=True)

กราฟ Bloch sphere แสดงการหมุนแกน Z โดยที่ ลูกศรสีเขียวอ่อนแสดงสถานะสุดท้าย
Phase encoding ถูกใช้ใน feature map เชิงควอนตัมหลายตัว โดยเฉพาะ feature map, feature map และ Pauli feature map ทั่วไป รวมถึงอื่นๆ
ทดสอบความเข้าใจ
อ่านคำถามด้านล่าง คิดคำตอบ แล้วคลิกสามเหลี่ยมเพื่อดูเฉลย
ต้องใช้ Qubit กี่ตัวในการใช้ phase encoding ตามที่อธิบายข้างต้นเพื่อเก็บ 8 คุณสมบัติ
คำตอบ: 8
เขียนโค้ดสำหรับเวกเตอร์ โดยใช้ phase encoding
คำตอบ:
อาจมีคำตอบหลายอย่าง นี่คือตัวอย่างหนึ่ง:
phase_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0]
qc = QuantumCircuit(len(phase_data))
for i in range(0, len(phase_data)):
qc.h(i)
qc.rz(phase_data[i] * 2 * math.pi / float(max(phase_data)), i)
qc.draw(output="mpl")

Dense angle encoding
Dense angle encoding (DAE) คือการรวมกันของ angle encoding และ phase encoding DAE ช่วยให้สามารถเข้ารหัสค่าคุณสมบัติสองค่าไว้ใน Qubit เดียวได้: หนึ่งมุมด้วยการหมุนแกน Y และอีกหนึ่งด้วยการหมุนแกน : โดยเข้ารหัสสองคุณสมบัติดังนี้:
การเข้ารหัสคุณสมบัติข้อมูลสองอย่างไว้ใน Qubit เดียวทำให้จำนวน Qubit ที่ต้องการลดลง ขยายไปยังคุณสมบัติมากขึ้น เวกเตอร์ข้อมูล สามารถเข้ารหัสได้ดังนี้:
DAE สามารถ generalize ไปยังฟังก์ชันใดก็ได้ของสองคุณสมบัติแทนที่จะเป็นฟังก์ชัน sinusoidal ที่ใช้ที่นี่ เรียกว่า general qubit encoding[7]
เพื่อเป็นตัวอย่างของ DAE โค้ดด้านล่างเข้ารหัสและแสดงภาพการเข้ารหัสคุณสมบัติ และ
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(3 * pi / 8, 0)
state2 = Statevector.from_instruction(qc)
qc.rz(7 * pi / 4, 0)
state3 = Statevector.from_instruction(qc)
states = state1, state2, state3
plot_Nstates(states, axis=None, plot_trace_points=True)

ทดสอบความเข้าใจ
อ่านคำถามด้านล่าง คิดคำตอบ แล้วคลิกสามเหลี่ยมเพื่อดูเฉลย
จากการอธิบายข้างต้น ต้องใช้ Qubit กี่ตัวในการเข้ารหัส 6 คุณสมบัติด้วย dense encoding
คำตอบ: 3
เขียนโค้ดเพื่อโหลดเวกเตอร์ ด้วย dense angle encoding
คำตอบ:
สังเกตว่าเราได้เติม "0" เพิ่มในรายการเพื่อหลีกเลี่ยงปัญหาที่มีพารามิเตอร์ที่ยังไม่ได้ใช้หนึ่งตัวในรูปแบบการเข้ารหัสของเรา
dense_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5, 0]
qc = QuantumCircuit(int(len(dense_data) / 2))
entry = 0
for i in range(0, int(len(dense_data) / 2)):
qc.ry(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.rz(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.draw(output="mpl")

การเข้ารหัสด้วย feature map ที่มีอยู่แล้ว
การเข้ารหัสที่จุดต่างๆ
Angle encoding, phase encoding และ dense encoding เตรียม product state โดยมีคุณสมบัติหนึ่งอยู่ใน Qubit แต่ละตัว (หรือสองคุณสมบัติต่อ Qubit) ซึ่งแตกต่างจาก basis encoding และ amplitude encoding ที่ใช้สถานะ entangle โดยไม่มีความสัมพันธ์แบบ 1:1 ระหว่างคุณสมบัติข้อมูลและ Qubit ใน amplitude encoding ตัวอย่างเช่น คุณสมบัติหนึ่งอาจเป็น amplitude ของสถานะ และอีกคุณสมบัติเป็น amplitude ของสถานะ โดยทั่วไป วิธีที่เข้ารหัสใน product state ให้ Circuit ที่ตื้นกว่าและสามารถเก็บ 1 หรือ 2 คุณสมบัติในแต่ละ Qubit ส่วนวิธีที่ใช้ entanglement และเชื่อมโยงคุณสมบัติกับสถานะแทนที่จะเป็น Qubit ให้ Circuit ที่ลึกกว่าและสามารถเก็บคุณสมบัติได้มากกว่าต่อ Qubit โดยเฉลี่ย
แต่การเข้ารหัสไม่จำเป็นต้องอยู่ใน product state ทั้งหมดหรือใน entangled state ทั้งหมดอย่าง amplitude encoding เลย ในความเป็นจริง รูปแบบการเข้ารหัสหลายแบบที่มีใน Qiskit ช่วยให้สามารถเข้ารหัสทั้งก่อนและหลัง entanglement layer แทนที่จะเป็นเพียงตอนต้น ซึ่งเรียกว่า "data reuploading" สำหรับงานที่เกี่ยวข้อง ดูอ้างอิง [5] และ [6]
ในส่วนนี้เราจะใช้และแสดงภาพรูปแบบการเข้ารหัสที่มีอยู่แล้วบางส่วน วิธีทั้งหมดในส่วนนี้เข้ารหัส คุณสมบัติเป็นการหมุนบน gate ที่มี parameter บน Qubit โดยที่ สังเกตว่าการเพิ่มสูงสุดของการโหลดข้อมูลสำหรับจำนวน Qubit ที่กำหนดไม่ใช่การพิจารณาเพียงอย่างเดียว ในหลายกรณีความลึกของ Circuit อาจเป็นการพิจารณาที่สำคัญกว่าจำนวน Qubit
Efficient SU2
ตัวอย่างที่พบบ่อยและมีประโยชน์ของการเข้ารหัสด้วย entanglement คือ Circuit efficient_su2 ของ Qiskit ที่น่าทึ่งคือ Circuit นี้สามารถเข้ารหัส 8 คุณสมบัติบนเพียง 2 Qubit ได้ ลองดูสิ่งนี้ แล้วพยายามทำความเข้าใจว่าเป็นไปได้อย่างไร
from qiskit.circuit.library import efficient_su2
circuit = efficient_su2(num_qubits=2, reps=1, insert_barriers=True)
circuit.decompose().draw(output="mpl")

เมื่อเราเขียนสถานะ เราจะใช้ convention ของ Qiskit ที่ Qubit ที่มีนัยสำคัญน้อยที่สุดอยู่ทางขวาสุด เช่น หรือ สถานะเหล่านี้สามารถซับซ้อนมากขึ้นอย่างรวดเร็ว และตัวอย่างที่หายากนี้อาจช่วยอธิบายว่าทำไมสถานะเหล่านี้จึงไม่ค่อยถูกเขียนออกมาอย่างชัดเจน
ระบบของเราเริ่มในสถานะ จนถึง barrier แรก (จุดที่เราเรียกว่า ) สถานะของเราเป็น:
นั่นคือ dense encoding ซึ่งเราได้เห็นแล้ว หลังจาก CNOT gate ที่ barrier ที่สอง () สถานะของเราคือ
ตอนนี้เราใช้การหมุน single-qubit ชุดสุดท้ายและรวม like state เพื่อได้:
สิ่งนี้อาจซับซ้อนเกินกว่าจะแยกแยะได้ แทนที่จะพยายามอ่าน ให้ถอยออกมาคิดว่าเราโหลดพารามิเตอร์ไปบนสถานะกี่ตัว: แปดตัว แต่เรามีเพียงสี่ computational basis state ในตอนแรกอาจดูเหมือนว่าเราโหลดพารามิเตอร์มากกว่าที่สมเหตุสมผล เนื่องจากสถานะสุดท้ายสามารถเขียนเป็น อย่างไรก็ตาม สังเกตว่า prefactor แต่ละตัวเป็น complex! เขียนแบบนี้:
จะเห็นได้ว่าเรามีพารามิเตอร์แปดตัวบนสถานะที่จะเข้ารหัสคุณสมบัติแปดอย่างของเราจริงๆ
ด้วยการเพิ่มจำนวน Qubit และจำนวนรอบของ entangling และ rotation layer สามารถเข้ารหัสข้อมูลได้มากขึ้นมาก การเขียนฟังก์ชันคลื่นออกมาจะกลายเป็นเรื่องที่ไม่สามารถทำได้อย่างรวดเร็ว แต่เรายังสามารถเห็นการเข้ารหัสในการทำงานได้
ที่นี่เราเข้ารหัสเวกเตอร์ข้อมูล ที่มี 12 คุณสมบัติ บน Circuit efficient_su2 3-Qubit โดยใช้แต่ละ gate ที่มี parameter เพื่อเข้ารหัสคุณสมบัติที่แตกต่างกัน
ในเวกเตอร์ข้อมูลนี้ คุณสมบัติแสดงตามลำดับที่กำหนด โดยลำพังแล้วไม่สำคัญว่าจะเข้ารหัสตามลำดับนี้หรือกลับกัน สิ่งที่สำคัญคือการติดตามและความสม่ำเสมอ สังเกตในแผนภาพ Circuit ว่า efficient_su2 ถือว่าลำดับการเข้ารหัสที่กำหนด โดยเฉพาะการเติม gate ที่มี parameter ชุดแรกจาก Qubit 0 ถึง Qubit 2 แล้วจึงไปยัง layer ถัดไป ซึ่งไม่สอดคล้องและไม่ขัดแย้งกับ little-endian notation เนื่องจากที่นี่คุณสมบัติข้อมูลไม่สามารถเรียงลำดับตาม Qubit ก่อน ที่ Circuit การเข้ารหัสจะถูกระบุ
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2]
circuit = efficient_su2(num_qubits=3, reps=1, insert_barriers=True)
encode = circuit.assign_parameters(x)
encode.decompose().draw(output="mpl")

แทนที่จะเพิ่มจำนวน Qubit คุณอาจเลือกเพิ่มจำนวนรอบของ entangling และ rotation layer แต่มีขีดจำกัดว่าจำนวนรอบที่มีประโยชน์มีเท่าใด ดังที่กล่าวไว้ก่อนหน้า มีการแลกเปลี่ยน: Circuit ที่มี Qubit มากขึ้นหรือมีรอบของ entangling และ rotation layer มากขึ้นอาจเก็บพารามิเตอร์ได้มากกว่า แต่ทำด้วยความลึกของ Circuit ที่มากขึ้น วิธีการเข้ารหัสไม่กี่วิธีถัดไปที่มีใน Qiskit มีคำว่า "feature map" เป็นส่วนหนึ่งของชื่อ ขอย้ำอีกครั้งว่าการเข้ารหัสข้อมูลไปยัง Circuit ควอนตัม คือ feature mapping ในแง่ที่มันนำข้อมูลไปยังปริภูมิใหม่: ปริภูมิ Hilbert ของ Qubit ที่เกี่ยวข้อง ความสัมพันธ์ระหว่างมิติของปริภูมิ feature เดิมและของปริภูมิ Hilbert จะขึ้นอยู่กับ Circuit ที่ใช้เข้ารหัส
feature map
feature map (ZFM) สามารถตีความได้ว่าเป็นการขยายตามธรรมชาติของ phase encoding ZFM ประกอบด้วย layer ของ single-qubit gate สลับกัน: layer ของ Hadamard gate และ layer ของ phase gate ให้เวกเตอร์ข้อมูล มี คุณสมบัติ Circuit ควอนตัมที่ทำ feature mapping แทนด้วย unitary operator ที่กระทำต่อสถานะเริ่มต้น:
โดย คือ ground state ของ Qubit สัญลักษณ์นี้ใช้เพื่อความสอดคล้องกับอ้างอิง [4] Havlicek et al. คุณสมบัติข้อมูล ถูกแมปแบบ one-to-one กับ Qubit ที่สอดคล้องกัน ตัวอย่างเช่น ถ้าคุณมี 8 คุณสมบัติในเวกเตอร์ข้อมูล คุณจะใช้ 8 Qubit Circuit ZFM ประกอบด้วย รอบของ subcircuit ที่ประกอบด้วย layer ของ Hadamard gate และ layer ของ phase gate Hadamard layer ประกอบด้วย Hadamard gate กระทำต่อทุก Qubit ใน -Qubit register ภายใน stage เดียวกันของอัลกอริทึม คำอธิบายนี้ยังใช้กับ phase gate layer ด้วย โดย Qubit ที่ ถูกกระทำโดย แต่ละ Gate มีคุณสมบัติหนึ่งเป็น argument แต่ phase gate layer () เป็นฟังก์ชันของเวกเตอร์ข้อมูล Circuit ZFM unitary ครบวงจรที่มีรอบเดียวคือ:
แล้ว รอบของ unitary นี้จะเป็น
คุณสมบัติข้อมูล ถูกแมปกับ phase gate ในลักษณะเดียวกันในทุก รอบ สถานะ ZFM feature map เป็น product state และมีประสิทธิภาพสำหรับการจำลองแบบ classical[4]
เริ่มต้นด้วยตัวอย่างขนาดเล็ก Circuit ZFM สอง Qubit ถูกเขียนโค้ดด้วย Qiskit และวาดเพื่อแสดงโครงสร้าง Circuit ที่เรียบง่าย ในตัวอย่างนี้ใช้รอบเดียว พร้อมเวกเตอร์ข้อมูล สังเกตว่านี่เขียนตามลำดับมาตรฐานของเวกเตอร์ใน Python หมายความว่าองค์ประกอบที่ คือ เราสามารถเลือกเข้ารหัสคุณสมบัติที่ นี้ไปยัง Qubit ที่ หรือ Qubit ที่ ก็ได้ อีกครั้ง ไม่สามารถมีการแมป 1:1 เดียวจากลำดับคุณสมบัติไปยังลำดับ Qubit ได้เสมอ เนื่องจาก feature map ที่แตกต่างกันเข้ารหัสคุณสมบัติจำนวนต่างกันไปยังแต่ละ Qubit สิ่งที่สำคัญคือเราต้องตระหนักว่าแต่ละคุณสมบัติถูกเข้ารหัสที่ไหน เมื่อให้รายการพารามิเตอร์แก่ feature map มันจะเข้ารหัสคุณสมบัติ 0 จากรายการไปยัง Qubit ที่มีนัยสำคัญน้อยที่สุดที่มี gate แบบ parameterized เช่น Qubit 0 เราจะปฏิบัติตาม convention นั้นเมื่อทำด้วยมือ เราจะเข้ารหัส บน Qubit ที่ และ บน Qubit ที่
Circuit unitary operator ของ ZFM กระทำต่อสถานะเริ่มต้นดังนี้:
สูตรถูกจัดเรียงใหม่รอบ tensor product เพื่อเน้นการดำเนินการบนแต่ละ Qubit โค้ด Qiskit ต่อไปนี้ใช้ Hadamard gate และ phase gate อย่างชัดเจนเพื่อแสดงโครงสร้างของ ZFM:
qc0 = QuantumCircuit(1)
qc1 = QuantumCircuit(1)
qc0.h(0)
qc0.p(pi / 2, 0)
qc1.h(0)
qc1.p(pi / 3, 0)
# Combine circuits qc0 and qc1 into 1 circuit
qc = QuantumCircuit(2)
qc.compose(qc0, [0], inplace=True)
qc.compose(qc1, [1], inplace=True)
qc.draw("mpl", scale=1)

ตอนนี้เราเข้ารหัสเวกเตอร์ข้อมูลเดิม ไปยัง Circuit ZFM ที่มีสามรอบ โดยใช้ class z_feature_map ของ Qiskit ซึ่งให้เราได้ quantum feature map ทั้งหมด โดย default ใน class z_feature_map พารามิเตอร์ จะถูกคูณด้วย 2 ก่อนแมปกับ phase gate เพื่อให้ได้การเข้ารหัสเดียวกับข้างต้น เราหารด้วย 2
from qiskit.circuit.library import z_feature_map
zfeature_map = z_feature_map(feature_dimension=2, reps=3)
zfeature_map = zfeature_map.assign_parameters([(1 / 2) * pi / 2, (1 / 2) * pi / 3])
zfeature_map.decompose().draw("mpl")

นี่เป็นการแมปที่แตกต่างจากที่ทำด้วยมือข้างต้นอย่างชัดเจน แต่สังเกตความสอดคล้องในการเรียงลำดับพารามิเตอร์: ถูกเข้ารหัสบน Qubit ที่ อีกครั้ง
คุณสามารถใช้ ZFM ผ่าน class ZFM ของ Qiskit ได้ หรือใช้โครงสร้างนี้เป็นแรงบันดาลใจในการสร้าง feature mapping ของตัวเอง
feature map
feature map (ZZFM) ขยาย ZFM ด้วยการรวม two-qubit entangling gate โดยเฉพาะ -rotation gate ZZFM ถูกคาดเดาว่าโดยทั่วไปแล้วมีราคาแพงในการคำนวณบนคอมพิวเตอร์แบบดั้งเดิม ซึ่งแตกต่างจาก ZFM
ทำ -interaction และมี entanglement สูงสุดที่ สามารถแยกสลายเป็นชุดของ gate บน two Qubit ดังที่แสดงในโค้ด Qiskit ต่อไปนี้โดยใช้ RZZ gate และ method decompose ของ QuantumCircuit เราเข้ารหัสคุณสมบัติเดียวของเวกเตอร์ข้อมูล :
qc = QuantumCircuit(2)
qc.rzz(pi, 0, 1)
qc.draw("mpl", scale=1)

ตามที่มักเกิดขึ้น เราเห็นสิ่งนี้แสดงเป็นหน่วยเดียวคล้าย gate จนกว่าเราจะใช้ .decompose() เพื่อดู gate ส่วนประกอบทั้งหมด
qc.decompose().draw("mpl", scale=1)

ข้อมูลถูกแมปด้วยการหมุนเฟส บน Qubit ที่สอง Gate entangle Qubit สองตัวที่มันกระทำด้วยระดับ entanglement ที่กำหนดโดยค่าคุณสมบัติที่เข้ารหัส
Circuit ZZFM ครบวงจรประกอบด้วย Hadamard gate และ phase gate เช่นเดียวกับ ZFM ตามด้วย entanglement ที่อธิบายข้างต้น รอบเดียวของ Circuit ZZFM คือ:
โดย มี ZZ-gate layer ที่มีโครงสร้างตาม entanglement scheme รูปแบบ entanglement หลายแบบแสดงในบล็อกโค้ดด้านล่าง โครงสร้างของ ยังรวมถึงฟังก์ชันที่รวมคุณสมบัติข้อมูลจาก Qubit ที่ถูก entangle ด้วยวิธีต่อไปนี้ สมมติว่า Gate จะถูกนำไปใช้กับ Qubit และ ใน phase layer Qubit เหล่านี้มี phase gate ที่เข้ารหัส และ ตามลำดับ argument ของ จะไม่ใช่เพียงคุณสมบัติใดคุณสมบัติหนึ่งเหล่านี้ แต่เป็นฟังก์ชันที่มักแทนด้วย (ไม่ควรสับสนกับมุมแอซิมัท):
เราจะเห็นสิ่งนี้ในตัวอย่างหลายตัวด้านล่าง การขยายไปยังหลายรอบเหมือนกับ z_feature_map:
เนื่องจาก operator มีความซับซ้อนมากขึ้น ลองเข้ารหัสเวกเตอร์ข้อมูล ด้วย two-qubit ZZFM และรอบเดียวโดยใช้โค้ดต่อไปนี้:
from qiskit.circuit.library import zz_feature_map
feature_dim = 2
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose(reps=1).draw("mpl", scale=1)

โดย default ใน Qiskit คุณสมบัติ จะถูกแมปเข้าด้วยกันกับ โดยฟังก์ชันการแมปนี้ Qiskit ให้ผู้ใช้ปรับแต่งฟังก์ชัน (หรือ ที่ คือเซตของ Qubit คู่ที่เชื่อมต่อผ่าน Gate ) เป็นขั้นตอน preprocessing
เมื่อขยายไปยังเวกเตอร์ข้อมูลสี่มิติ และแมปกับ four-qubit ZZFM ที่มีรอบเดียว เราสามารถเริ่มเห็นการแมป สำหรับ Qubit คู่ต่างๆ นอกจากนี้เราสามารถเห็นความหมายของ "linear" entanglement:
feature_dim = 4
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose().draw("mpl", scale=1)

ใน linear entanglement scheme คู่ Qubit ที่เป็นเพื่อนบ้านกัน (ตามหมายเลข) ใน Circuit นี้จะถูก entangle มี entanglement scheme ที่มีอยู่แล้วอื่นๆ ใน Qiskit ได้แก่ circular และ full
Pauli feature map
Pauli feature map (PFM) คือ generalization ของ ZFM และ ZZFM ให้ใช้ Pauli gate แบบ arbitrary Pauli feature map มีรูปแบบที่คล้ายคลึงกับ feature map สองตัวก่อนหน้ามาก สำหรับ รอบของการเข้ารหัส คุณสมบัติของเวกเตอร์
สำหรับ PFM ถูก generalize ให้เป็น Pauli expansion unitary operator ที่นี่เราแสดงรูปแบบทั่วไปมากขึ้นของ feature map ที่พิจารณาจนถึงตอนนี้:
โดย คือ Pauli operator ที่นี่ คือเซตของการเชื่อมต่อ Qubit ทั้งหมดตามที่ feature map กำหนด รวมถึงเซตของ Qubit ที่ถูกกระทำโดย single-qubit gate นั่นคือ สำหรับ feature map ที่ Qubit 0 ถูกกระทำโดย phase gate และ Qubit 2 และ 3 ถูกกระทำโดย Gate เซต จะรวม วิ่งผ่านองค์ประกอบทั้งหมดของเซตนั้น ใน feature map ก่อนหน้า ฟังก์ชัน เกี่ยวข้องกับเฉพาะ single-qubit gate หรือเฉพาะ two-qubit gate เท่านั้น ที่นี่เราให้นิยามทั่วไป:
สำหรับเอกสาร ดู เอกสาร class Pauli feature map ของ Qiskit) ใน ZZFM operator ถูกจำกัดให้เป็น
วิธีหนึ่งในการเข้าใจ unitary ข้างต้นคือการเปรียบเทียบกับ propagator ในระบบทางกายภาพ unitary ข้างต้นคือ evolution operator แบบ unitary สำหรับ Hamiltonian ที่คล้ายกับ Ising model โดยพารามิเตอร์เวลา ถูกแทนที่ด้วยค่าข้อมูลเพื่อขับเคลื่อนการวิวัฒนาการ การขยาย unitary operator นี้ให้ Circuit PFM การเชื่อมต่อ entangling ใน สามารถตีความได้ว่าเป็น Ising coupling ใน spin lattice
ลองพิจารณาตัวอย่างของ Pauli และ operator ที่แทน interaction ประเภท Ising เหล่านี้ Qiskit มี class pauli_feature_map สำหรับสร้าง PFM โดยเลือก single- และ -qubit gate ซึ่งในตัวอย่างนี้จะถูกส่งเป็น Pauli string 'Y' และ 'XX' โดยทั่วไป คือ 1 หรือ 2 สำหรับ single- และ two-qubit interaction ตามลำดับ entanglement scheme คือ "linear" หมายความว่ามีเฉพาะ Qubit ที่เป็นเพื่อนบ้านกันใน Circuit ควอนตัมที่ถูกเชื่อมต่อ สังเกตว่านี่ไม่ได้สอดคล้องกับ Qubit ที่เป็นเพื่อนบ้านกันบนคอมพิวเตอร์ควอนตัมจริง เนื่องจาก Circuit ควอนตัมนี้เป็น abstraction layer
from qiskit.circuit.library import pauli_feature_map
feature_dim = 3
pfmap = pauli_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1, paulis=["Y", "XX"]
)
pfmap.decompose().draw("mpl", scale=1.5)

Qiskit มีพารามิเตอร์ ใน Pauli feature map เพื่อควบคุมการปรับขนาดของ Pauli rotation
ค่า default ของ คือ ด้วยการ optimize ค่าของมันในช่วง เช่น สามารถทำให้ quantum kernel สอดคล้องกับข้อมูลได้ดีขึ้น
แกลเลอรีของ Pauli feature map
ที่นี่เราแสดงภาพ Pauli feature map ต่างๆ สำหรับ Circuit สอง Qubit เพื่อให้เห็นภาพที่ดียิ่งขึ้นของขอบเขตความเป็นไปได้
from qiskit.visualization import circuit_drawer
import matplotlib.pyplot as plt
feature_dim = 2
fig, axs = plt.subplots(9, 2)
i_plot = 0
for paulis in [
["I"],
["X"],
["Y"],
["Z"],
["XX"],
["XY"],
["XZ"],
["YY"],
["YZ"],
["ZZ"],
["X", "ZZ"],
["Y", "ZZ"],
["Z", "ZZ"],
["X", "YZ"],
["Y", "YZ"],
["Z", "YZ"],
["YY", "ZZ"],
["XY", "ZZ"],
]:
pfmap = pauli_feature_map(feature_dimension=feature_dim, paulis=paulis, reps=1)
circuit_drawer(
pfmap.decompose(),
output="mpl",
style={"backgroundcolor": "#EEEEEE"},
ax=axs[int((i_plot - i_plot % 2) / 2), i_plot % 2],
)
axs[int((i_plot - i_plot % 2) / 2), i_plot % 2].title.set_text(paulis)
i_plot += 1
fig.set_figheight(16)
fig.set_figwidth(16)
สิ่งข้างต้นสามารถขยายออกได้อีกเพื่อรวม permutation และ repetition อื่นๆ ของ Pauli matrix ผู้เรียนได้รับการสนับสนุนให้ทดลองกับตัวเลือกเหล่านั้น
ทบทวน feature map ที่มีอยู่แล้ว
คุณได้เห็นรูปแบบหลายอย่างในการเข้ารหัสข้อมูลไปยัง Circuit ควอนตัม:
- Basis encoding
- Amplitude encoding
- Angle encoding
- Phase encoding
- Dense encoding
คุณได้เห็นวิธีสร้าง feature map ของตัวเองโดยใช้รูปแบบการเข้ารหัสเหล่านี้ และคุณได้เห็น feature map ที่มีอยู่แล้วสี่ตัวที่ใช้ประโยชน์จาก angle encoding และ phase encoding:
- Efficient SU2
- Z feature map
- ZZ feature map
- Pauli feature map
feature map ที่มีอยู่แล้วเหล่านี้แตกต่างกันในหลายด้าน:
- ความลึกสำหรับจำนวนคุณสมบัติที่เข้ารหัสที่กำหนด
- จำนวน Qubit ที่ต้องการสำหรับจำนวนคุณสมบัติที่กำหนด
- ระดับของ entanglement (เกี่ยวข้องอย่างชัดเจนกับความแตกต่างอื่นๆ)
โค้ดด้านล่างนำ feature map ที่มีอยู่แล้วสี่ตัวนี้ไปใช้กับการเข้ารหัสของชุดคุณสมบัติ และ plot ความลึก two-qubit ของ Circuit ที่ได้ เนื่องจาก error rate ของ two-qubit gate สูงกว่า error rate ของ single-qubit gate มาก จึงอาจสนใจความลึกของ two-qubit gate เป็นพิเศษ ในโค้ดด้านล่าง เราได้จำนวน gate ทั้งหมดใน Circuit โดยการ decompose Circuit ก่อนแล้วใช้ count_ops() ดังที่แสดงด้านล่าง ที่นี่ two-qubit gate ที่เราสนใจคือ Gate cx:
# Initializing parameters and empty lists for depths
x = [0.1, 0.2]
n_data = []
zz2gates = []
su22gates = []
z2gates = []
p2gates = []
# Generating feature maps
for n in range(3, 10):
x.append(n / 10)
zzcircuit = zz_feature_map(n, reps=1, insert_barriers=True)
zcircuit = z_feature_map(n, reps=1, insert_barriers=True)
su2circuit = efficient_su2(n, reps=1, insert_barriers=True)
pcircuit = pauli_feature_map(n, reps=1, paulis=["XX"], insert_barriers=True)
# Getting the cx depths
zzcx = zzcircuit.decompose().count_ops().get("cx")
zcx = zcircuit.decompose().count_ops().get("cx")
su2cx = su2circuit.decompose().count_ops().get("cx")
pcx = pcircuit.decompose().count_ops().get("cx")
# Appending the cx gate counts to the lists. We shift the zz and Pauli data points,
# because they overlap.
n_data.append(n)
zz2gates.append(zzcx - 0.5)
z2gates.append(0)
su22gates.append(su2cx)
p2gates.append(pcx + 0.5)
# Plot the output
plt.plot(n_data, p2gates, "bo")
plt.plot(n_data, zz2gates, "ro")
plt.plot(n_data, su22gates, "yo")
plt.plot(n_data, z2gates, "go")
plt.ylabel("CX Gates")
plt.xlabel("Data elements")
plt.legend(["Pauli", "ZZ", "SU2", "Z"])
# plt.suptitle('zz_feature_map(n)')
plt.show()
โดยทั่วไป Pauli feature map และ ZZ feature map จะให้ความลึกของ Circuit และจำนวน 2-qubit gate ที่มากกว่า efficient_su2 และ Z feature map
เนื่องจาก feature map ที่มีใน Qiskit สามารถใช้งานได้กว้างขวาง เราจึงมักไม่จำเป็นต้องออกแบบของตัวเองโดยเฉพาะในระยะการเรียนรู้ อย่างไรก็ตาม ผู้เชี่ยวชาญด้านการเรียนรู้ด้วยเครื่องเชิงควอนตัมมักจะกลับมาสู่หัวข้อการออกแบบ feature mapping ของตัวเอง เมื่อพวกเขาเผชิญกับความท้าทายที่ซับซ้อนสองอย่าง:
-
ฮาร์ดแวร์ยุคใหม่: การมีอยู่ของ noise และค่าใช้จ่ายสูงของ error-correcting code หมายความว่าแอปพลิเคชันในปัจจุบันจะต้องพิจารณาเรื่องต่างๆ เช่น hardware efficiency และการลดความลึกของ two-qubit gate
-
การแมปที่เหมาะสมกับปัญหาในมือ: เป็นเรื่องหนึ่งที่จะบอกว่า
zz_feature_mapตัวอย่างเช่น จำลองได้ยากบนคอมพิวเตอร์แบบดั้งเดิม ดังนั้นจึงน่าสนใจ แต่อีกเรื่องหนึ่งคือการที่zz_feature_mapเหมาะสมอย่างยิ่งกับ machine learning task หรือชุดข้อมูล ของคุณ ประสิทธิภาพของ parameterized quantum circuit ที่แตกต่างกันบนข้อมูลประเภทต่างๆ ยังเป็นพื้นที่การสืบสวนที่ยังคงดำเนินอยู่
เราสรุปด้วยหมายเหตุเกี่ยวกับ hardware efficiency
Hardware-efficient feature mapping
Hardware-efficient feature mapping คือการแมปที่คำนึงถึงข้อจำกัดของคอมพิวเตอร์ควอนตัมจริง เพื่อลด noise และ error ในการคำนวณ เมื่อรัน Circuit ควอนตัมบนคอมพิวเตอร์ควอนตัม near-term มีกลยุทธ์หลายอย่างในการลด noise ที่มีอยู่ในฮาร์ดแวร์ กลยุทธ์หลักสำหรับ hardware efficiency คือการลดความลึกของ Circuit ควอนตัมเพื่อให้ noise และ decoherence มีเวลาน้อยลงในการทำให้การคำนวณเสียหาย ความลึกของ Circuit ควอนตัมคือจำนวน gate step ที่จัดเรียงตามเวลาที่จำเป็นในการดำเนินการคำนวณทั้งหมด (หลังการ optimize Circuit)[5] จำไว้ว่าความลึกของ Circuit ตรรกะแบบ abstract อาจต่ำกว่าความลึกมากหลังจาก Circuit ถูก Transpile สำหรับคอมพิวเตอร์ควอนตัมจริงมาก
Transpilation คือกระบวนการแปลง Circuit ควอนตัมจาก abstraction ระดับสูงเป็นแบบที่พร้อมรันบนคอมพิวเตอร์ควอนตัมจริง โดยคำนึงถึงข้อจำกัดของฮาร์ดแวร์ คอมพิวเตอร์ควอนตัมมี single- และ two-qubit gate ดั้งเดิมชุดหนึ่ง ซึ่งหมายความว่า gate ทั้งหมดในโค้ด Qiskit ต้องถูก Transpile ให้เป็นชุดของ gate ฮาร์ดแวร์ดั้งเดิม ตัวอย่างเช่น ใน ibm_torino ซึ่งเป็น QPU ที่ใช้ Heron r1 processor และสร้างเสร็จในปี 2023 gate ดั้งเดิมหรือ basis gate คือ {CZ, ID, RZ, SX, X} ได้แก่ two-qubit controlled-Z gate และ single-qubit gate ที่เรียกว่า identity, -rotation, square root of NOT และ NOT ตามลำดับ ให้ชุดทั่วไป เมื่อนำ multi-qubit gate ไปใช้เป็น subcircuit ที่เทียบเท่า ต้องใช้ physical two-qubit gate พร้อมกับ single-qubit gate อื่นๆ ที่มีในฮาร์ดแวร์ นอกจากนี้ เพื่อทำ two-qubit gate บนคู่ Qubit ที่ไม่ได้เชื่อมต่อทางกายภาพ SWAP gate จะถูกเพิ่มเพื่อย้ายสถานะ Qubit ระหว่าง Qubit เพื่อให้สามารถ coupling ได้ ซึ่งนำไปสู่การขยาย Circuit ที่หลีกเลี่ยงไม่ได้ การใช้ argument optimization ที่ตั้งค่าได้จาก 0 ถึงระดับสูงสุด 3 สำหรับการควบคุมและปรับแต่งที่มากขึ้น pipeline ของ Transpiler สามารถจัดการได้ด้วย Qiskit Pass Manager ดู เอกสาร Qiskit Transpiler สำหรับข้อมูลเพิ่มเติมเกี่ยวกับ Transpilation
ใน Havlicek et al. 2019 [2] วิธีหนึ่งที่ผู้เขียนบรรลุ hardware efficiency คือการใช้ feature map เนื่องจากเป็นการขยายลำดับที่สอง (ดูส่วน " feature map" ข้างต้น) การขยายลำดับ มี -qubit gate คอมพิวเตอร์ควอนตัม IBM® ไม่มี -qubit gate ดั้งเดิมที่ ดังนั้นการนำไปใช้ต้องการการแยกสลายเป็น two-qubit CNOT gate ที่มีในฮาร์ดแวร์ อีกวิธีหนึ่งที่ผู้เขียนลดความลึกคือการเลือก coupling topology ที่แมปตรงกับ architecture coupling โดยตรง การ optimize เพิ่มเติมที่พวกเขาทำคือการมุ่งเป้า subcircuit ฮาร์ดแวร์ที่มีประสิทธิภาพสูงและมีการเชื่อมต่อที่เหมาะสม สิ่งเพิ่มเติมที่ควรพิจารณาคือการลดจำนวนรอบของ feature map และการเลือก entanglement scheme ความลึกต่ำหรือ "linear" แบบกำหนดเองแทน scheme "full" ที่ entangle Qubit ทั้งหมด

กราฟิกข้างต้นแสดงเครือข่ายของ node และ edge ที่แทน physical Qubit และ hardware coupling ตามลำดับ coupling map และประสิทธิภาพของ ibm_torino แสดงพร้อม two-qubit CZ coupling gate ที่เป็นไปได้ทั้งหมด Qubit มีรหัสสีตามมาตราส่วนที่อิงจากเวลา T1 relaxation เป็นไมโครวินาที (μs) โดย T1 ที่นานกว่าดีกว่าและมีสีอ่อนกว่า coupling edge มีรหัสสีตาม CZ error โดยสีเข้มกว่าดีกว่า ข้อมูลเกี่ยวกับ hardware specification สามารถเข้าถึงได้ใน hardware backend configuration schema IBMQBackend.configuration()
อ้างอิง
- Maria Schuld and Francesco Petruccione, Supervised Learning with Quantum Computers, Springer 2018, doi:10.1007/978-3-319-96424-9.
- Vojtech Havlicek et al., "Supervised Learning with Quantum Enhanced Feature Spaces." Nature, vol. 567 (2019): 209–212. https://arxiv.org/abs/1804.11326.
- Ryan LaRose and Brian Coyle, "Robust data encodings for quantum classifiers", Physical Review A 102, 032420 (2020), doi:10.1103/PhysRevA.102.032420, arXiv:2003.01695.
- Lou Grover and Terry Rudolph. "Creating Superpositions That Correspond to Efficiently Integrable Probability Distributions." arXiv:quant-ph/0208112, August 15, 2002, https://arxiv.org/abs/quant-ph/0208112.
- Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, José I. Latorre, "Data re-uploading for a universal quantum classifier", Quantum 4, 226 (2020), ArXiv.org/abs/1907.02085.
- Maria Schuld, Ryan Sweke, Johannes Jakob Meyer, "The effect of data encoding on the expressive power of variational quantum machine learning models", Phys. Rev. A 103, 032430 (2021), arxiv.org/abs/2008.08605
import qiskit
qiskit.version.get_version_info()